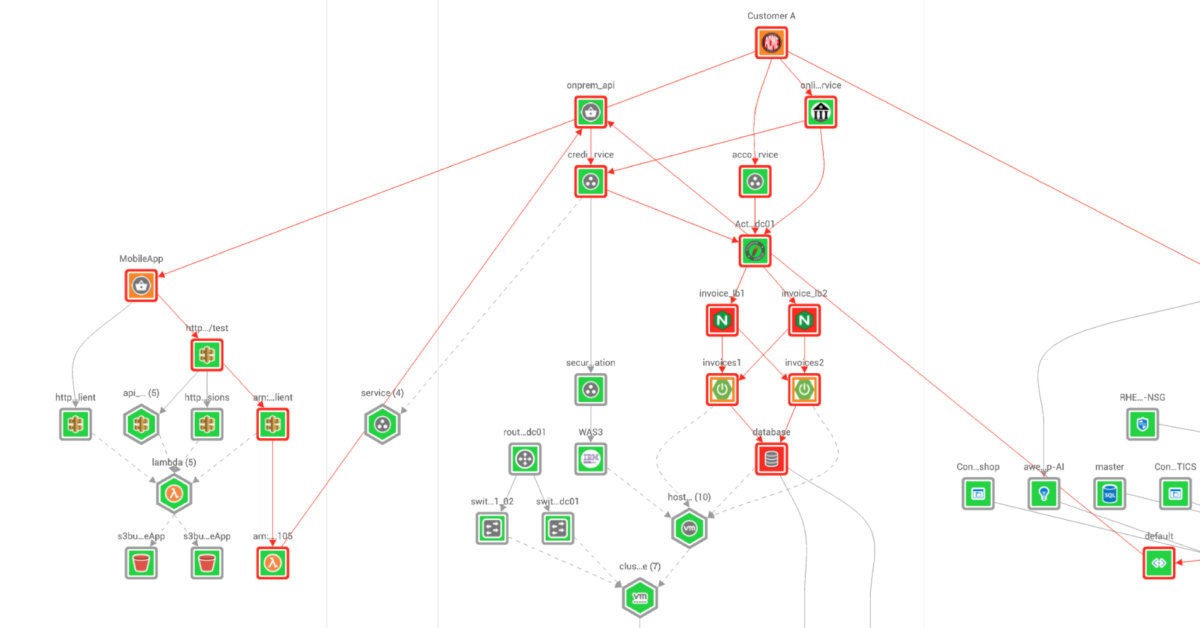
A view into topology allows similar visibility. You can see how components of an IT system are laid out to interact with each other. The components, like towns in Google Maps, are connected to each other, and you can see the various connections—similar to roads, streets, and highways—that link everything together.
One of the simplest topologies is point-to-point, where you have computer A directly connected to computer B. You can also have a point-to-point topology where two local area networks (LANs), network A and network B, are connected.
If you throw switches into the mix, you can give what is a pretty simple topology a brain. The switch decides which computer handles what and when. This is called a star topology, with the switch sending out messages like the sun sending out rays of light.
Topology also applies to applications, containers and databases. Because they are often interdependent elements of a service, the ways in which different components interact can have a significant effect on the end user’s experience. In addition, because topologies change all the time, it can be tough to keep up. If you've ever used Google Maps after a street has been changed but Maps hasn't been updated, you know how frustrating and confusing it can be.
Similarly, unless your topology is mapped out dynamically to reflect current changes, you're likely to find yourself lost as you try to pinpoint issues or engineer new efficiencies.
Challenges to Achieving a Comprehensive Cross-Domain Topology
With full-stack observability, you can integrate several pieces of your hybrid, dynamic IT environment and therefore gain visibility into why and how issues arise. Not surprisingly, this comes with some challenges.
Information lives in silos
Silos can be the enemy of an effective topology. Since the advent of computing, information has been kept in silos, categorized according to the process that produced it or the app that used it. But in an environment with topology-powered observability, information from several different sources can be normalized and correlated by the observability solution. Without this capability, the end result is silos of information that are incomplete, inaccurate or produced inefficiently. This makes managing an IT environment - and ensuring the reliability of it - challenging.
In the modern business environment, the silo situation is exacerbated, particularly because there are so many tools for monitoring and understanding the environment. While this type of monitoring produces useful data, it's often limited to a small part of the environment and not integrated with data from the rest of the system. What results are sets of disconnected data. The lack of integration makes it hard to see how different systems impact each other. When issues occur between silos that have inter-dependencies, forget about quickly finding root cause.
It’s constantly changing
Humans are creatures of habit, and habit doesn’t like change. If you rely on humans to update your topology, you will fail. Topology needs to be agile, reflexive and even proactive in the way it solves business problems.
Full-Stack Observability With StackState
StackState gives you full-stack observability and a set of capabilities that allow you to monitor your processes in real time, enabling you to pinpoint exactly where and when an issue arose. StackState’s time-traveling capability can bring you back in time to the exact moment when an issue originated, allowing you to troubleshoot in moments and discover novel ways of improving the experience of the end user.
StackState’s observability solution is built on an understanding of how the different elements of your topology—containers, databases, applications, switches, endpoints and more—work together. The platform can trace the ripple effect of an issue back to the original pebble, enabling you to make changes, if necessary, to your
topology to improve usability and performance. You can also use StackState to
look into the future, enabling you to predict the impact of performance anomalies on your business—from how applications function all the way through to your revenue stream.
To know more, book a free guided demo with us or get in touch with a relationship-based topology expert today.


