
Techstrong Research surveyed 543 IT professionals around the globe, across 20 industries. The largest concentration of respondents were in the telecommunications, technology, Internet and electronics sectors, followed by financial services.
Several aspects of observability the research focused on include:
Observability adoption
Business goals organizations have for observability
Struggles organizations are facing in adopting observability
How organizations assess their observability practices across four levels of maturity and whether AIOps is becoming part of observability practices
Adoption levels of OpenTelemetry
Here are highlights of the research, though not all that the report covers. Get the full report, from the StackState website.
Observability adoption
64% of survey respondents have adopted observability. Though responsibility for observability can reside in a number of areas, by far the most dominant group owning observability today is still IT operations (41%), followed by DevOps (29%) and then less so by platform teams (12%), site reliability engineering (11%) and security (8%).
Observability is an easier adoption for those who have embraced monitoring and are using tools like Dynatrace, CloudWatch, Datadog and others. The growth in observability over the last several years has been tremendous, and for good reason. With the constant rate of change in IT environments and rapid technology adoption, managing a reliable IT stack is no easy feat. Monitoring on its own is no longer enough. IT needs more insight into the internal health state of components across the entire IT stack than a simple “on/off” status from monitoring provides. Additionally, when things fail, it is important to be able to quickly determine what the root cause of that failure was and the full impact it had across your entire infrastructure. Part of being able to see the full impact includes the ability to see the interdependencies of components.
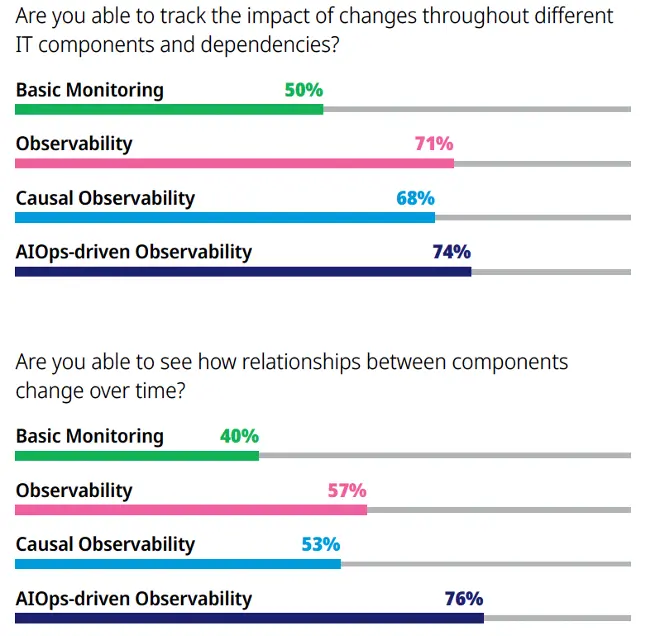
Monitoring, alone, cannot provide this level of deep insight into your stack, as shown by two stats from the survey results (see below). As you can see, there is a significant upward trajectory in ability to get deeper insights into the IT environment for those organizations who have moved beyond monitoring and into even basic observability, with greater benefits as they move upward in the maturity of their practices.
The bar charts, below, show the percentage of respondents who responded “yes” to each question.
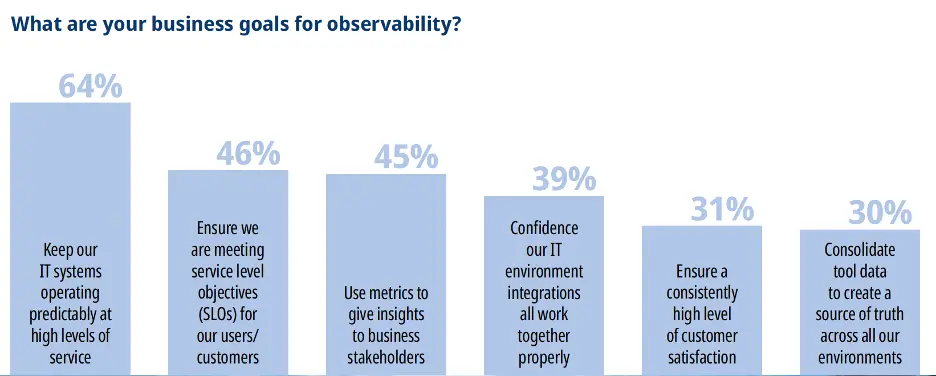
Business goals for observability
Respondents highlighted the goals they have for observability. The top benefits cited are:
The ability to provide a high level of service availability in complex environments of cloud, mobile, on-premise and legacy technologies. Today’s IT environments are dynamic, with containers coming and going, cloud services spinning up and down, application and infrastructure updates, configuration changes. The list goes on. Observability is critical in ensuring maximum uptime and availability.
Ability to meet or exceed service level objectives (SLOs). Need we say more? This is a significant focus in any IT environment today.
Gaining a unified view and understanding of interrelationships between various components within multiple and diverse systems. This is essential, to understand how various components are interdependent on each other. When a failure occurs and the beeper goes off at 2:00 am, the triage person needs to quickly determine, for example, that a failure in component B was caused by an earlier failure in component A.
Data consolidation and elimination of data silos. Many organizations started out with monitoring a key component and as their stack expanded, additional monitoring tools were added by other teams within the company to monitor additional key services. Over time, the stack became a mix of data silos and multiple monitoring tools, with no insights into how each silo can impact the other and, when an error occurs, where it started and who owns remediation of it. Further, when an issue occurs across siloed services, correlation of data from each silo in order to get at root cause can be a very real issue for teams.
Identifying problems more quickly, in order to maximize system availability and minimize MTTR and downtime.
More intelligent alerting – reduction in alert storms and even adoption of proactive alerting to prevent issues from even occurring.
Struggles faced in adopting observability
You can look at the struggles in adopting observability as almost the inverse of the benefits in adopting it. Survey respondents were asked in what areas their team or company struggles the most as they try to implement observability.
The three top struggles were all ranked essentially equal, with a fourth close behind:
Too many tools that aren’t integrated (41%), therefore no ability to truly get an accurate picture of what’s going on across the services and/or teams using different tools.
Having enough knowledge within teams to implement observability (40%).
Gaining visibility in one place across all systems, teams and tech platforms to understand the overall health of the IT environment (40%).
Too many tools, generating too much data that cannot be correlated to gain a holistic understanding of what’s going on within our stack (34%).
Other responses were:
Providing metrics, logs and traces to the different application teams who need the data (24%).
Too many alerts without context and/or alert storms (22%).
Leveraging accurate observability/insights to power automated self-healing systems (16%).
These responses all indicate the realities of IT environments today. IT is managing environments that are complex, have many tools in use and are generating reams of telemetry data from many different and diverse applications. It is no wonder observability uptake is exploding. Observability is critical in managing all of these very complicated aspects of an IT stack.
Observability maturity within organizations
Though monitoring has been well-established within IT for a couple of decades, observability is a relatively recent IT addition. Interestingly, the term “observability,” coined by engineer Rudolf E. Kálmán in 1960, has its roots in control theory , the mathematical study of systems – from industrial processes to aircraft – with the goal of operating those systems in safe and efficient ways.
TechHQ describes observability as follows: “…a system is observable if its internal state can be inferred from external outputs. In fact, it might not even be possible to know exactly how fast a chemical reaction is occurring, for example, but we can measure temperature and other indicators to help us build models of what is happening inside a processing unit.”
The research report categorizes the current state of observability maturity into four levels*. Survey takers were asked to place their organization into one of the following four levels of maturity (with level 1 being the least mature; level 4 being the most mature):

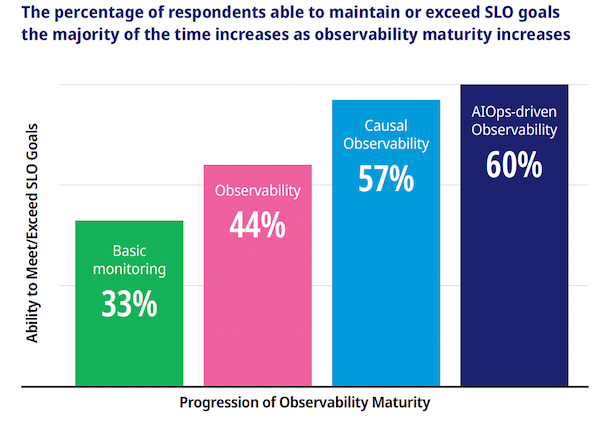
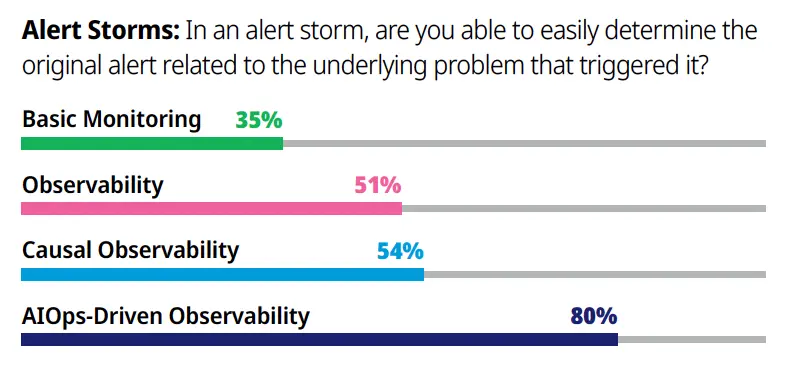
Not surprisingly, the vast majority of organizations are at Level 1: Basic Monitoring (35%) or Level 2: (Basic) Observability (34%), almost 70% between the two. However, those operating their observability practices at higher levels – either Level 3: Causal Observability or Level 4: AIOps-Driven Observability – are extracting maximum value for their efforts.
The research showed that those operating at the highest level of observability maturity, AIOps-driven observability, meet SLOs more consistently, become aware of issues faster, proactively prevent issues more frequently, deal more effectively with alert storms including involving the right people right away and with fuller context than those in any other level.
[*Note: We have written extensively about observability maturity. Please download our white paper, “The Observability Maturity Model,” for a detailed discussion about observability maturity, including characteristics of each level and the value your organization can realize as you mature your observability practice.]
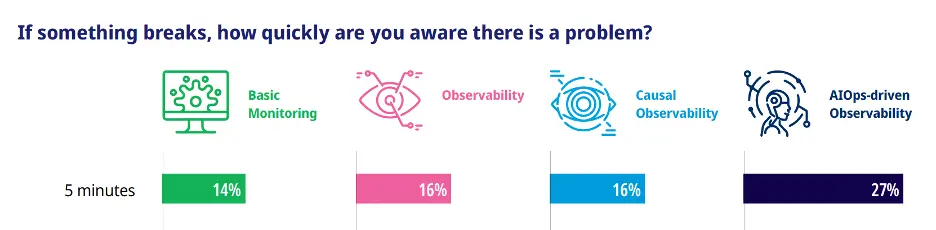
Additionally, those at the highest level of maturity, AIOps-Driven Observability, are able to detect issues within five minutes - almost twice as fast as those in the other maturity levels.
Finally, in dealing with alert storms, those again at the highest level of observability maturity (AIOps-driven Observability) are able to easily determine the initial alert triggered by the underlying issue. Obviously, this saves valuable time and resources in getting to root cause analysis, solving the issue and restoring service levels.
The growing importance of OpenTelemetry in observability
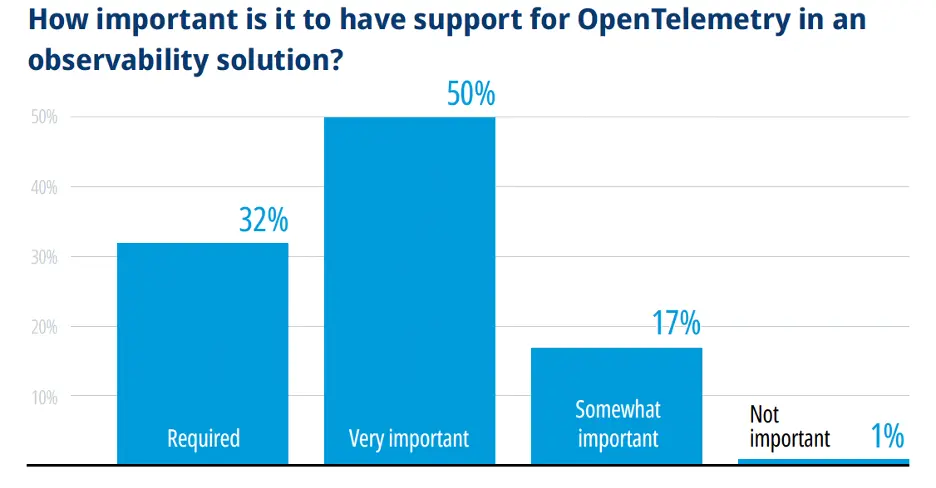
Not surprisingly, the adoption of OpenTelemetry , a vendor-neutral open source project within the Cloud Native Computing Foundation (CNCF), is significant with 32% of respondents indicating it is required and 50% indicating it is very important in vendor products.
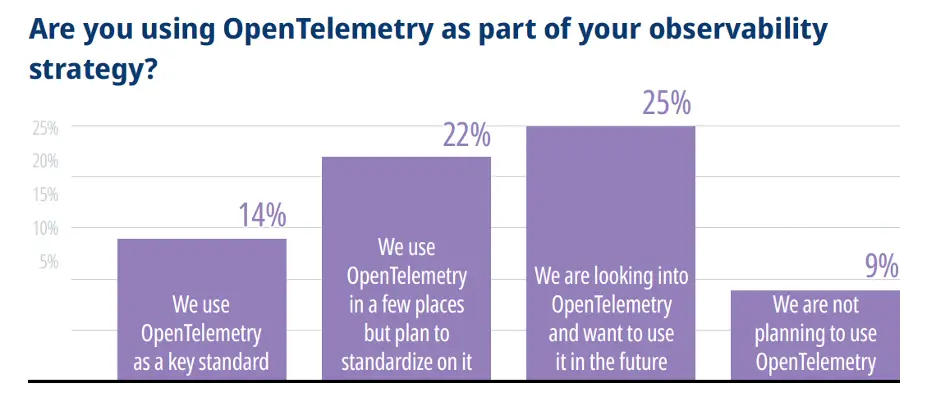
Slightly more than one third (36%) of respondents use OpenTelemetry within their organization already. However, adoption is still in early stages as only 14% had adopted it as a standard, with another 22% using it in a few places but not having yet standardized on it.
Though only 34% of respondents are using OpenTelemetry as either a key standard or in some areas, 82% felt that it was required or very important to have OpenTelemetry support in observability solutions:
On its website, the OpenTelemetry project describes itself as, “…a collection of tools, APIs and SDKs. Use it to instrument, generate, collect and export telemetry data (metrics, logs and traces) to help you analyze your software’s performance and behavior.”
Conclusion
Traditional practices and tools for monitoring, triage and debugging were designed for legacy systems much less complex than those we typically manage today. Established during the era of monolith and SOA applications, traditional monitoring, debugging and triage solutions are inadequate to understand the inner workings and breadth of known and unknown states new application software, cloud native technologies, microservices and dynamic infrastructure may exhibit. Observability addresses these needs and can support IT in managing a robust and resilient infrastructure.
This blog only covers some of the highlights of the research. Download the full report (below) and read more about where observability is at today!


