Why IT Observability?
One term keeps popping up to tackle rapid changes in the IT operations landscape: observability. Due to the complexity of the IT world we live in today, observability is becoming extremely important. Because of the influence observability has on IT, it's essential to know everything about observability. If you're already familiar with observability and want to take a deep-dive, we recommend you download this white paper called "Redefining Observability: A 3-Step Approach for Gaining Control in Fast-Changing IT Landscapes." But if you're still a little bit unfamiliar with observability, it might be a smart move to read this blog post first, before you download the white paper.
What is observability?
In short, observability extends the principles of IT monitoring by pulling together data from logs, metrics, traces and events to empower operators to identify the root cause of issues and resolve them quickly. That's where most definitions of observability stop. We believe that this definition falls short. Data will still be too siloed when you pull together logs, metrics, traces and events. You won't be able to identify and solve the root cause of any issues that occur. To redefine observability, we wrote a white paper to come up with a definition of observability that's more practical.
Redefining observability in three steps
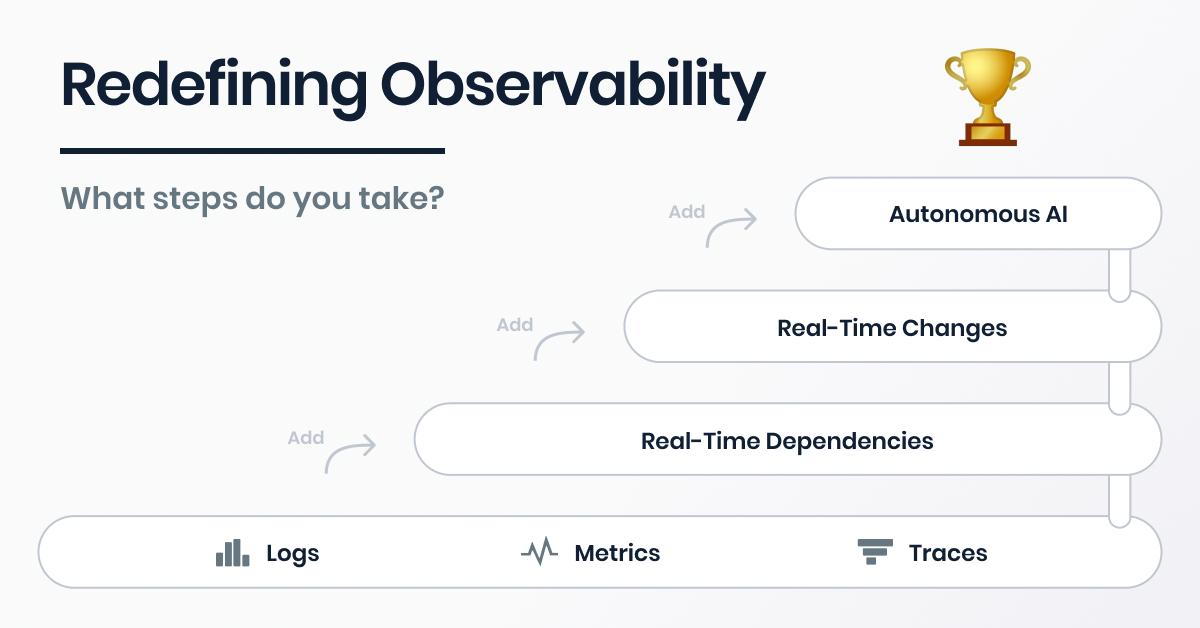
Many teams use observability to get control over fast-changing IT infrastructures. However, when IT incidents inevitably occur, actionable insights to resolve conflicts instantly are still siloed. The white paper shows you three steps to gain control in fast-changing IT landscapes. In short, the three steps are:
✅ Adding real-time topology
✅ Tracking all real-time changes
✅ Adding autonomous AI
These three steps are explained in more detail in the Redefining Observability white paper. It also shows you what you will need to implement these three steps into your own IT infrastructure to pinpoint the root cause of an issue faster. Read the white paper and learn more about:
✔️ What traditional observability is and why it falls short
✔️ Why topological analysis is crucial for your observability strategy
✔️ How you can crush MTTR
About StackState
StackState's topology-powered observability lets you more effectively manage your dynamic IT environment by unifying performance data from your existing monitoring tools into a single topology. This enables you to:
✔️ Decrease MTTR: Reduce MTTR up to 80% or more (average StackState customer result) by quickly identifying root cause and alerting the right teams with the actionable information necessary to resolve the issue.
✔️ Fewer outages: Reduce the number of outages by 65% or more through topology-powered observability and by adding more predictability with AIOps capabilities.
✔️ Faster, more frequent releases: Increase application releases by 3x or more by giving time back to developers who would otherwise be chasing infrastructure outages and issues.


