Letting the problem manifest itself
A trick I learned early in life, instead of calling out in frustration, is just letting a problem manifest itself. Give one last written warning, move on and wait for the wound to infect. Nothing will motivate people as pain. Of course this should be an absolute last resort.
Visualize
The thing is, to have a discussion about information technology with non-engineers is pretty hard. This is for a large part caused by the fact that they can’t see, touch, smell, hear, taste or interact with the technology in any way. We need to relate to something to understand it. Few people understand how a mobile phone works, but everybody knows what it is. That’s why the moment you draw a box around a concept on a whiteboard it immediately becomes easier to understand. A few boxes and arrows can get you a long way in bootstrapping understanding. However, this too is hard. It requires a lot of knowledge to get such a drawing right and it can be pretty hard to get accurate or up to date. That’s why fundamental problems often get fixed when they start to cause trouble. Then when that crisis team is formed, all of the sudden all that knowledge comes together, decision makers are incentivized and miracles are worked.
Don’t rely on a few wise men, but notice the early warning signs
Of course, it is not a solution to rely on an a few wise men to save the day when all hell breaks lose, when months before some engineer within that same company already suspected something might break, but could not get his or her message across. Or when some component was already reporting warnings for a long time, but people failed to notice, because it was just one of many warning and the consequences of that one particular warning turning into a full-blown error were not known to the people receiving them. The solution is to notice the warning signs.
Give everybody insight in the IT infrastructure so as to understand the signs
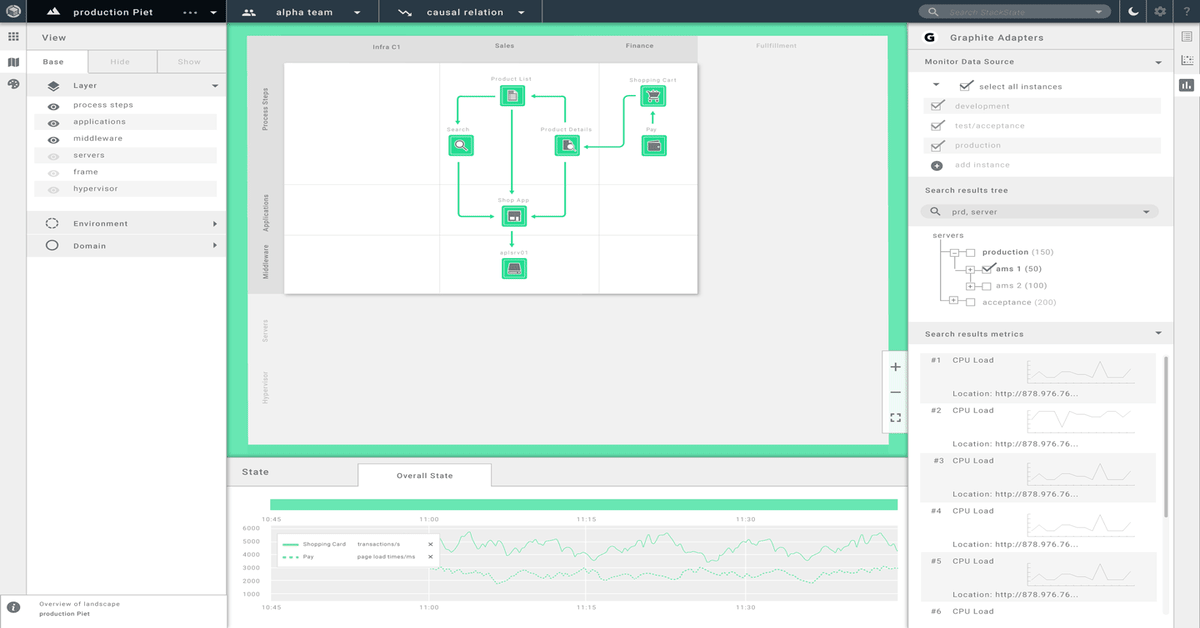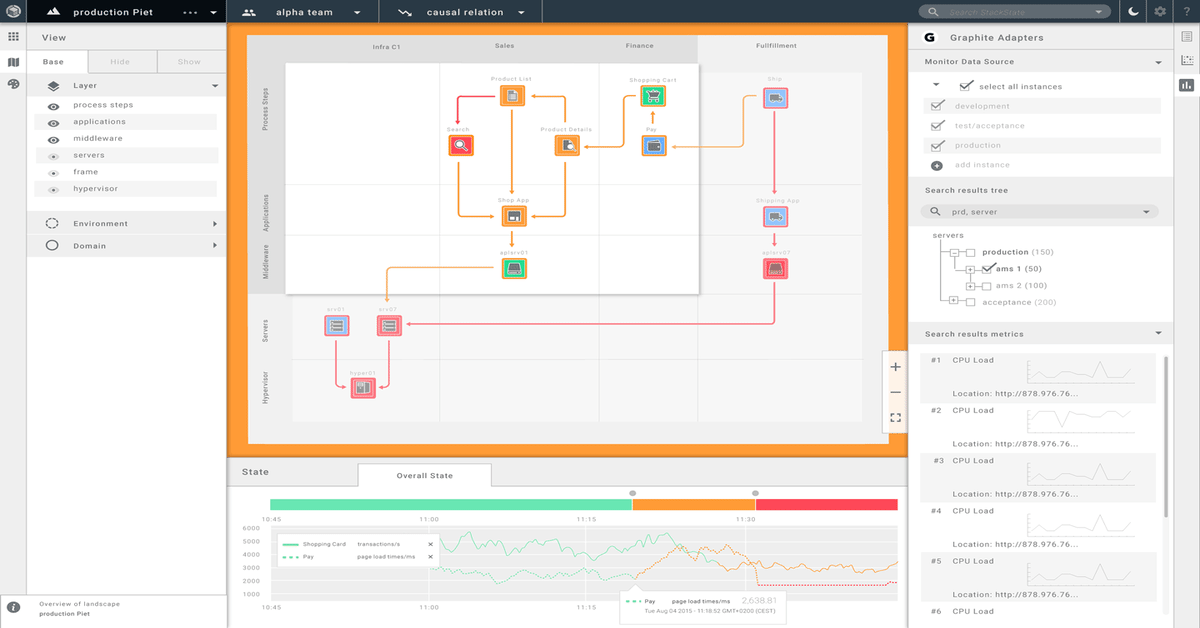
Everybody within a company should be able to see all parts of the IT infrastructure and how other parts of the stack relate to the parts they work on in order for them to understand what is important and what is not. Why would you continue laying bricks when the floor is starting to crack open? There are way too many surprises in IT still, simply because of its intangible nature; the crack is too often invisible until the whole floor collapses. Most of the time the signs are there, but they did not reach the people who could actually do something about it fast enough or they were not convinced that the consequences of ignoring the signs could be so dramatic.
A realtime visual model is fundamental to the smooth operation of an IT infrastructure
At StackState we believe that Full Chain Monitoring and an up-to-date and accurate visual overview of any sizable IT infrastructure, the stack and its state, are fundamental to its smooth operation. By its visual nature it becomes more tangible and therefore easier to understand and communicate about. There are less surprises, because everybody can see what is happening or about to happen when some issues are not resolved. Decisions are made better and faster when the decision makers are able to see the cracks appearing. And finally, problems are resolved quicker, because it is easier to distinguish between cause and effect.
An up to date IT infrastructure model is the basis for advanced future functions
An accurate and up-to-date model of your IT infrastructure not only assists smooth operations though. That is just one of its many applications. Such a model could be used as the basis for predictive analytics, running simulations, distributed cooperative work, post mortems, self-healing processes, capacity planning, runtime cost reductions, architectural decision making and more.


