
Site reliability engineering (SRE) is what you get when you treat operations as if it’s a software problem. The mission of an SRE practice is to protect, provide for and progress the software and systems offered and managed by an organization with an ever-watchful eye on their availability, latency, performance and capacity.1
So says Google , recognized as the founder of the concept of site reliability engineering. By 2016, Google had over 1,000 site reliability engineers.2 According to the Upskilling 2021 Report by DevOps Institute, 22% of organizations in a survey of 2,000 respondents had adopted the site reliability engineering model.3 Just one year later, DevOps Institute has released their first Global SRE Pulse Report 2022 and found that, one year after the original survey, 62% of survey respondents have adopted some level of SRE. Admittedly only 19% have implemented it across their organization, but 55% have adopted it within specific teams. The remaining responders say they are piloting it (25%) or failed at it (1%).
In this blog, we’ll break down some of the key highlights from the Global SRE Pulse report. The research was conducted based on a survey of over 460 SRE leaders and practitioners. The resulting report offers a deep dive into the state of SRE adoption, deployment and automation.
Treating operations as a software problem means process automation. It means driving forward new technologies, such as full stack observability, and being able to support continuous everything as businesses large and small strive to undergo digital transformation, with an end goal of being nimble and agile in competitive markets. Part of being nimble and agile is also having services that offer as close to zero downtime as possible, or said another way, offer maximum uptime. The goal of the Global SRE Pulse Report was to identify the state of SRE adoption, deployment and automation in the quest for zero downtime.
SRE in practice…and SRE practices
Companies of all sizes are undergoing digital transformation. The term is now so overused that it’s become an eye-roller, a catch-all for anything related to driving automation and streamlined processes throughout an organization. However, companies undergo digital transformations because they see benefit in delivering higher quality applications to their customers faster and more cost effectively. In some highly competitive industries, it’s transform or perish. If you can’t be nimble in turning your business on a dime or leapfrogging your competitors, you could very well find yourself in last place.
With the continuous everything trend and need to move fast, IT environments have become more dynamic than ever before. Containers spin up and down, sometimes only lasting for minutes or hours. Networks, applications and cloud components are updated, deployed or deprecated. Software releases may be deployed every minute, hour or week. In short, there is constant change occurring in today’s complex IT environments. Due to this high rate of change, the vast majority of incidents today are caused by change. Thus, the emergence - and importance - of SRE practices and the site reliability engineer role. With 62% of Pulse Report survey respondents saying they have embraced SRE to some level, the practice is here to stay, and for good reason.
An effective SRE practice can increase site reliability and prevent unplanned downtime. A more reliable site can also increase customer or user satisfaction with the application or service they are using. We already talked earlier about the importance of maintaining competitive leadership. In diagram 1, below, we list from the report some of the other reasons given as reasons to adopt SRE.
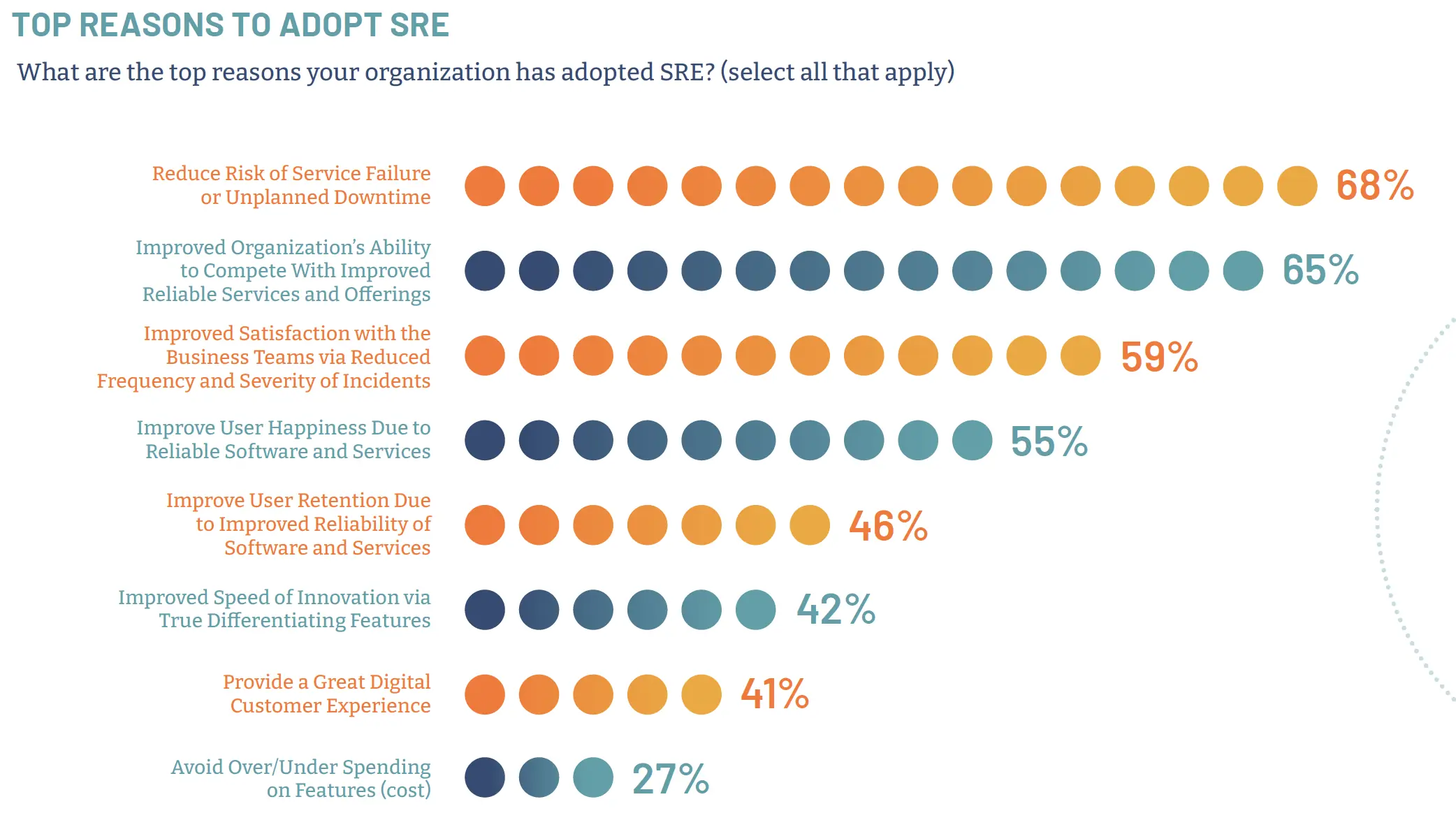
Challenges to implementing SRE
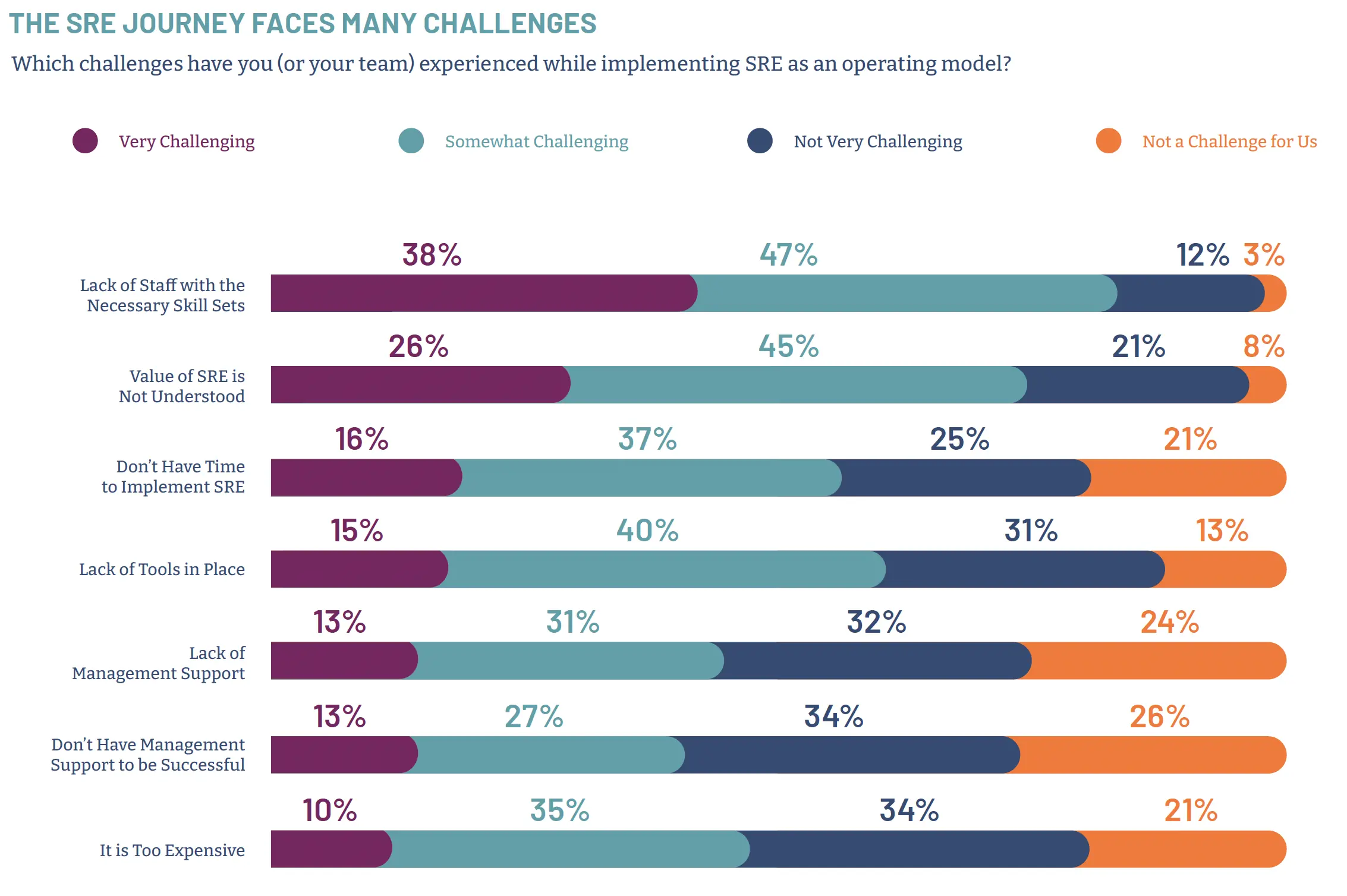
However, like anything worth doing (think DevOps, digital transformation) you don’t flip a switch and do SRE. A well-oiled SRE machine doesn’t happen overnight. The biggest challenge pointed out by 85% of the Pulse Report survey takers was finding the right skills for SRE to work. Additional challenges come from a lack of understanding of the value of SRE, no time to implement it, a lack of tools in place and the lack of management support. See Table 1, below, for the challenges the survey identified.
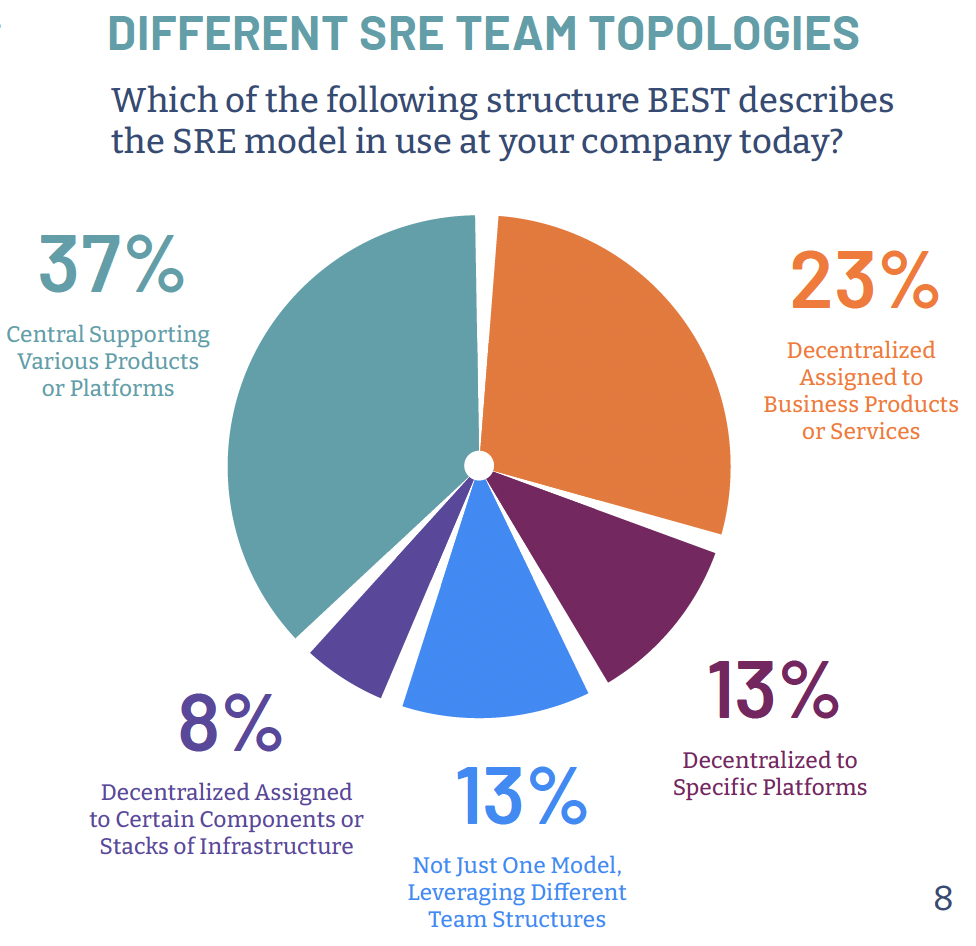
Site reliability engineering team topologies
As SRE practices grow in organizations, everyone wants to know, how is a site reliability engineering practice organized? What is the perfect organizational structure? The answer is, there is no perfect structure. It can vary greatly from company to company. The top two topologies, though, are centralized or decentralized. In fact, 37% of SRE practices are organized in a central model, supporting various products or platforms. 23% are organized in a decentralized model, assigned to specific products or services. The rest are combinations of centralized and decentralized.
Not surprisingly, the largest share of SRE teams still report into IT operations. That “largest share” is only 30%. This is somewhat surprising in that site reliability engineering seems like a natural offshoot of IT operations.
Defining the role of site reliability engineer
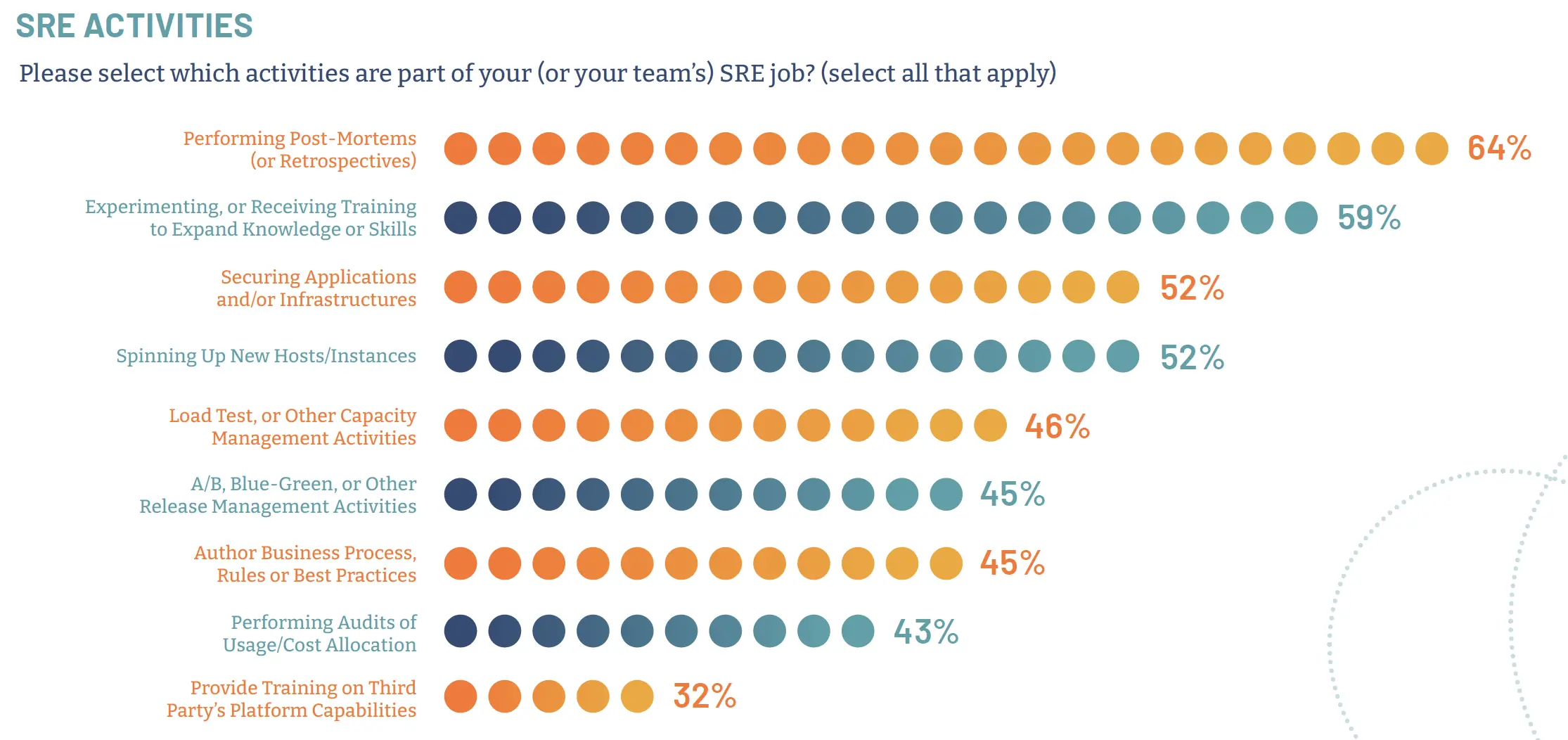
SREs perform a diverse set of activities, some development-related and some operations-related. Figure 4, below, shows some of the activities SREs engage in. This role must continuously improve the reliability of systems and help with troubleshooting. Since the applications and systems they oversee are expected to be highly automated and self-healing, SREs have time to experiment, develop and document best practices and create processes.
SRE culture
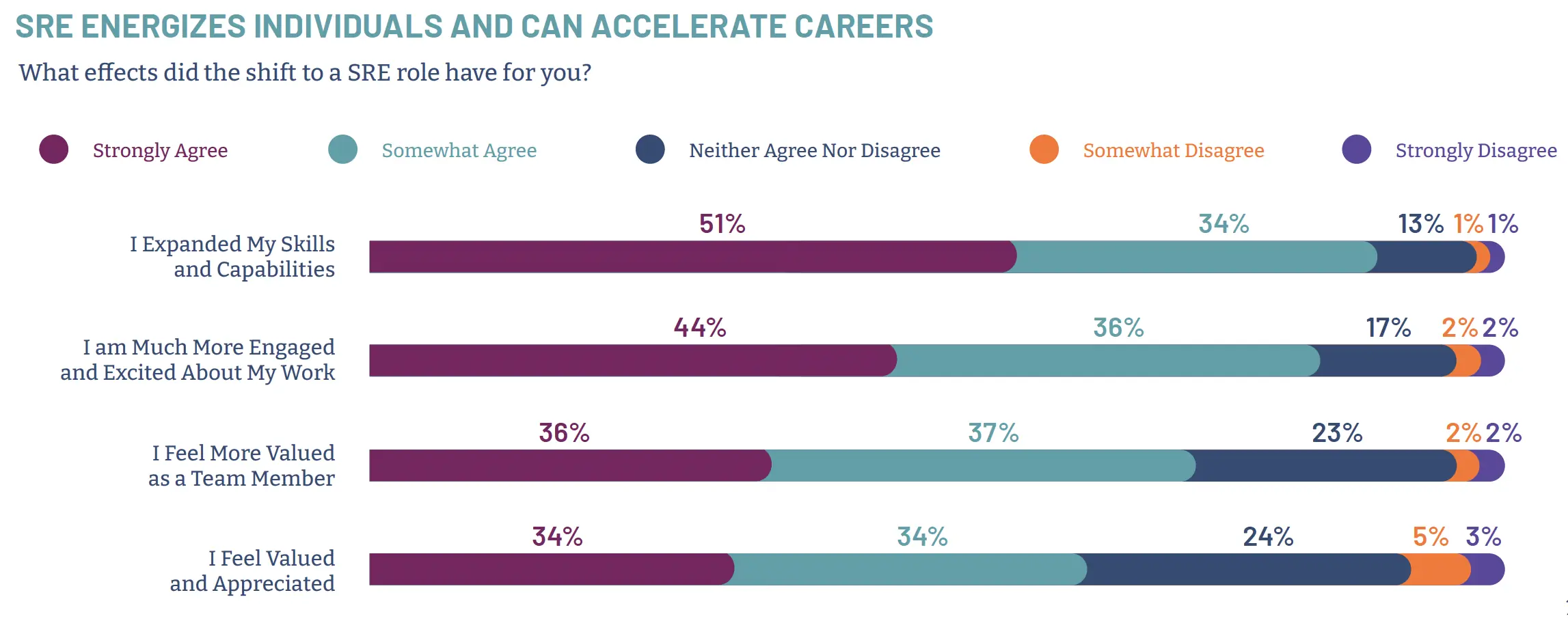
Implementation of a site reliability engineering practice is a journey – it takes a deliberate, coordinated motion and must have the full support of management. It requires consistent commitment, as it is a job that is never done. There are always new issues to tackle, new ways to consider implementing more reliable processes and automating them into the IT stack. However, the Pulse Report showed that working in an SRE team is a rewarding experience (see diagram 5, below), according to 44% of the respondents. Site reliability engineers have a great opportunity to re-energize their careers – and, in line with this, 50% of respondents said they have expanded their skills and capabilities. They are also part of a new engineering practice, are learning new things and making a difference for their organizations. All of this also comes with attractive compensation, on average 10-20% higher than system engineers or system admins.
The culture generally within SRE teams is similar to that of DevOps. Individuals are respected, there is a sense of teamwork and no finger pointing when things go wrong. Building strong, collaborative and committed teams at all levels of the organization – with the full support of management - is important for success.
The role of observability in SRE practices
So far, we have talked about the importance of site reliability engineering in keeping your IT stack up and reliable. We’ve also discussed the need for processes and tooling to proactively prevent issues from even happening. Given the complexity of today’s IT environments, achieving reliability and proactively preventing incidents are impossible tasks without the right tools. Observability is one of those tools. Observability goes hand-in-hand with a successful SRE practice. The survey indicated observability to be the second most important automation tool currently being implemented within organizations, along with application performance monitoring (APM) and configuration management. A full 92% of respondents were in various levels of implementing observability.
Speaking of APM, many organizations today have monitoring. Monitoring has been around for several decades and is a good initial step to building a reliable IT system. However, monitoring only gives you basic information, such as are my monitored components working or not? Is performance acceptable, or not? Monitoring doesn’t answer questions such as, “Why is my system not working?” “What change caused an incident and when did that change occur?” “How did that change impact a component and propagate through my stack, based on component dependencies?” “How can I proactively prevent such incidents in the future?” These are the questions only observability can answer. Observability is critical to getting the necessary insights into complex IT architectures and software stacks.
To keep a site reliable and optimize uptime, you need deep insights that you can only get from observability, a natural next step to take to mature your SRE practice. StackState provides a unique approach to observability. Our full stack observability provides a complete picture of the state of your stack at every moment in time, combining telemetry and trace data from all sources in your IT stack into a unified topology. StackState will alert when issues occur, help to pinpoint root cause and help you resolve issues quickly. We can even help you to prevent issues with our advanced Automatic Anomaly Detector and AIOps capabilities - speeding your path to becoming a zero-downtime enterprise.
Summary
Given the rate of change in today’s IT environments, SRE practices are more important than ever to ensure reliability across your IT stack. Reliability ensures that a company can continuously deliver its products or services to its customers and be agile in response to market dynamics. Digital transformation and the constant change that comes with it had already started the trend towards SRE practices. The COVID-19 pandemic fueled that growth, by creating a real sense of urgency around site reliability, as digital offerings became critical for many industries in order to survive. Today, 62% of organizations now have some level of SRE adoption.
In short, the Global SRE Pulse Report 2022 contains really insightful information about the role of site reliability engineering practices and the importance of the site reliability engineers that run them. I hope this brief overview entices you to download the full report and learn more about the state of SRE.
Additional Resources
References
1What is Site Reliability Engineering (SRE)?, Google
2Site reliability engineering , Wikipedia
3Upskilling Report 2021 , DevOps Institute


