An example for which Deep Learning is used are spam filters. Spam filters have been around for a while and are able to filter out unwanted emails with extreme high precision. Not many people understand how these unwanted emails are separated from the wanted emails. This is understandable as spam filters are incredibly complex. There are several reasons. First of all, you can not simply filter based on sender address, as new spam addresses can easily be created. The second reason is that spam is often send from legitimate email accounts hijacked by third parties. The best way to separate unwanted emails is to look at the content of the email messages. The most effective techniques to do this are based on machine learning.
Machine learning is a disciple which concerns itself with the development of self learning systems. These systems learn in an automated fashion to recognise structure in data. In this way the system learns a model that explains the data that enables us to do predictions over unseen data. Well known examples of machine learning are face recognition, voice recognition and text translation. Another great example is the self driving car from Google. This car is loaded with different kinds of machine learning systems to recognise pedestrians and traffic signs.
The underlying principle
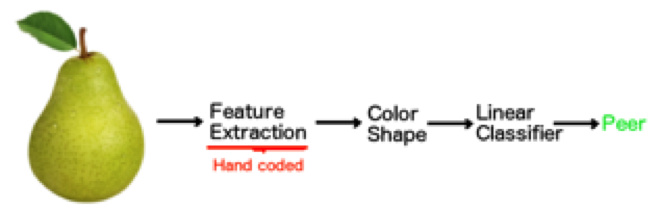
The principle behind machine learning is rather simple. Imagine we want to build a machine that separates apples from pears. A digital image is made of an object, and two values called features are extracted from this digital image by a small piece of hand written code. The code extracts the color of the object in the image from red to green and the shape of the object from circular to oval. Now imagine we have a set of images containing both apples and pears. For each image we also know if it contains an apple or a pear, we call these the labels of the images. When we compute the features for the images of the training set and plot them we get the following graphs.
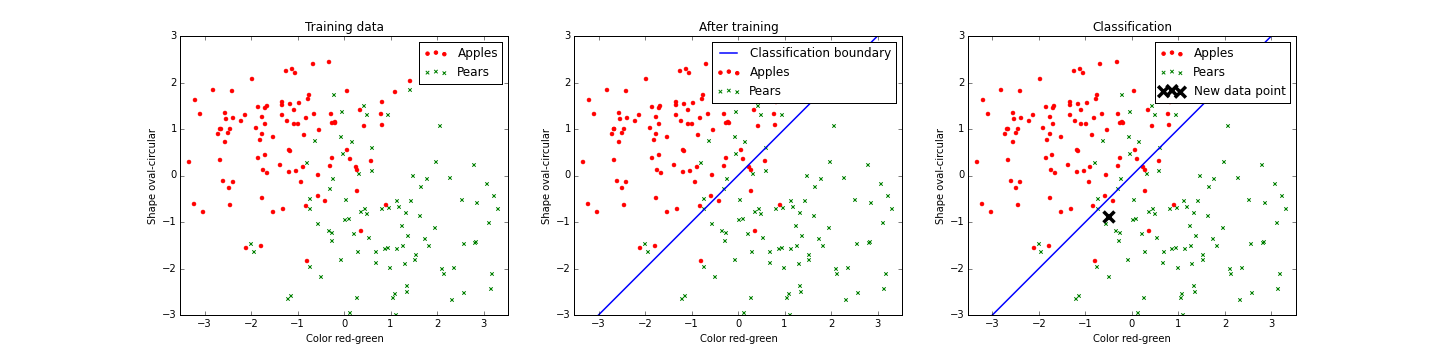
We see that apples and pears mostly occupy their own areas. Both object classes are therefore largely separable by separating the space into two distinct spaces (blue line). Given a new image of an object we can now identify it as an apple or a pear by computing the features and checking in which space it lays. In essence, the algorithm has learned from data to differentiate apples from pears.
Although this is the case we also see that the system can make mistakes if the computed features are close to the line separating the two object classes. This is because there exist green oval apples and more round red pears. The accuracy of the algorithm is therefore highly dependable on the number of samples in the training set and the quality and number of features used. For example, we could have used a third feature that would quantify the texture of the object. This might have increased the accuracy of the algorithm. The whole process is schematically visualized in the figure below.
Deep Learning
The above described method is the essence of machine learning and has been applied in this manner for decades. The most important element is constructing quality features such that object categories are separable. One might ask however, is it also possible to learn these features directly, instead of hand coding them? This is indeed possible, and methods to do so have existed since the seventies. One method which can be used to learn features automatically is neural networks. Neural networks are loosely based on the way the brain works.
Artificial neural networks are made up of artificial neurons that model single brain cells. These artificial neurons represent one unit of computation. An artificial neural network receives different values as input (for example from other artificial neurons) and then computes a simple equation to produce a single output value. This output value may then functions as the input for other neurons. By connecting neurons, in layers, we construct one big artificial neural network. Although single neurons perform simple computations the network as a whole can perform a very complex calculation. The image below illustrates this idea, with neurons represented as circles and output-input connections between neurons as lines. The interesting thing about neural networks is that they automatically learn the features required. We can imagine a neural network that can separate apples and pears by learning the shape and color features directly from images it receives as input.
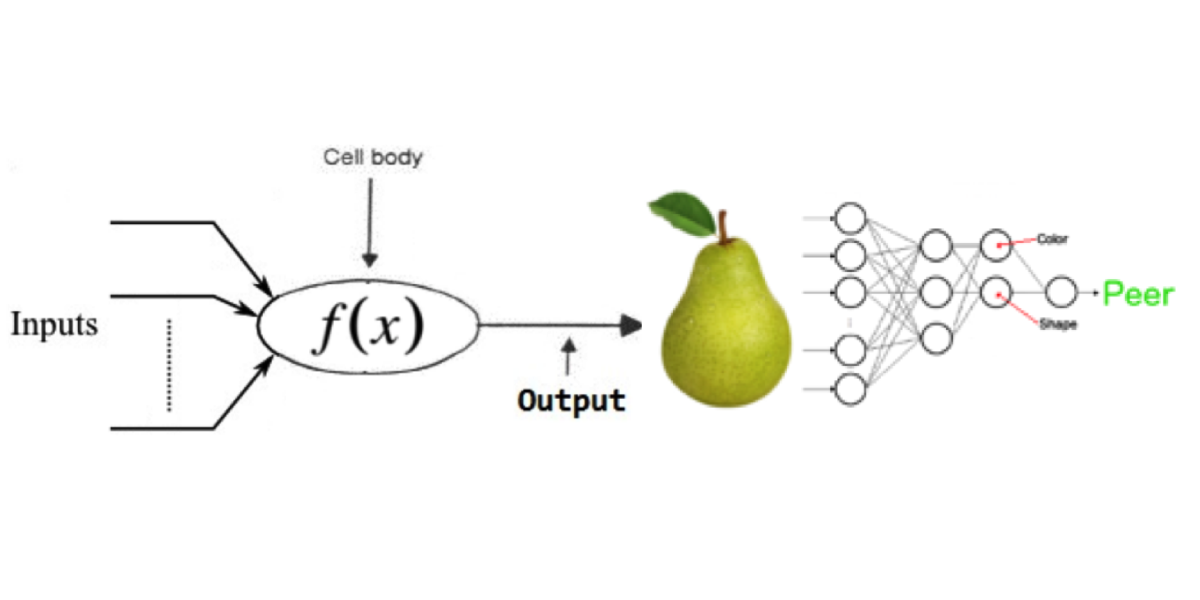
The term deep learning refers to the number of layers in the neural network, also called the depth of network. The depth plays an important role in learning good features. This is because every layer learns a set of features based on the features learned in the layer before. The deeper the network the more complex the features that can be learned. A nice demo that gives more insight into how neural networks work can be found by following the link: playground.tensorflow.org.
Although neural networks learn the features by themselves, they weren’t often applied in practice. The reason for this is two fold. First of all, many training examples are required, second many layers are needed to learn good features, which in turn requires a lot of computational power. With the rise of big data and an increase in computational power over the last few years it has become possible to apply these neural networks in practice. Neural networks can learn far more complex features then can be constructed by hand. Therefore they often outperform systems normally coded by hand.
Applications
Machine learning and deep learning are widely applicable and are not limited to separating pears and apples for industrial agriculture. For example, systems exist that learn to identify cancer cells from healthy cells in medical scans. The accuracy of these kinds of systems has improved rapidly over the last few years. Facebook for example has create a Siri like system that is capable of analyzing the content of pictures with a high degree of accuracy and can then answer questions about the image content .
Although these kinds of systems do not perform better than humans yet, there exist more specialised system that already outperform humans. For example an application by Microsoft recognizes dog breeds with high accuracy, outperforming humans.
Machine learning is not only used for classification but is also used for analyzing text. A neural network can for example be used to extract the sentiment of text. This indicates how positive or negative the text is. This is a well known technique used to automatically asses the content of product reviews for example.
The most impressive application of machine learning in my opinion is in the field of artificial intelligence. By combination of neural networks with reinforcement learning it is possible to construct intelligent agents that can learn from there environment.
The best example of this, is a system produced by Google DeepMind which learns to play Atari video games like pong and breakout completely autonomously by trial and error. The system only receives screen input and can only produces button presses on the video game controller, just like a human. In some video games the system actually outperforms humans.
Anomaly Detection
One of the areas StackState AIOps is currently focusing our attention on is the applicability of deep learning in the context of anomaly detection in signals (streams). This means detecting if we see abnormal patterns in signals compared to the normally observed frequently occurring patterns.
The aim is to use anomaly detection in StackState's full-stack observability platform to detect problems before they escalate and become catastrophic. This way the problem can be resolved faster allowing for shorter down times. Thesis based on the premise that abnormal behavior precedes system failure.
Anomaly Detection & Deep Learning
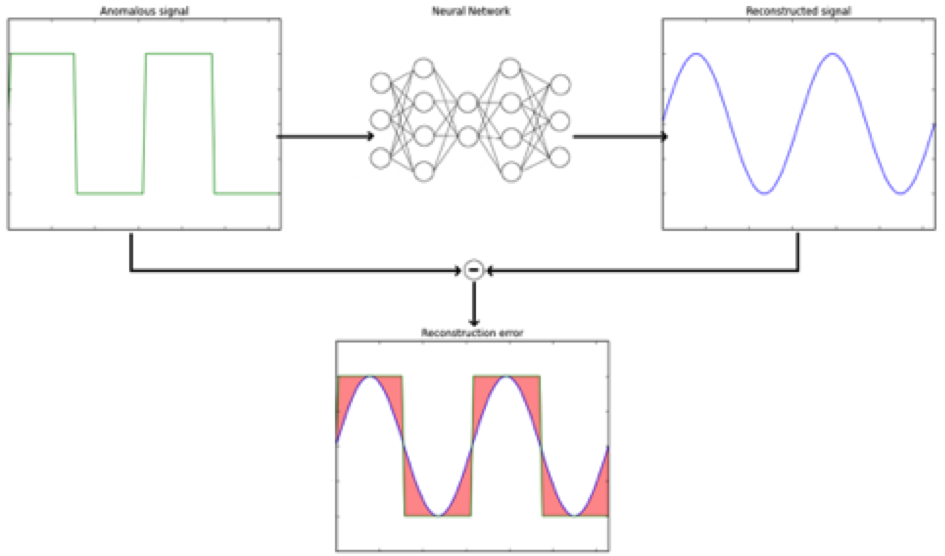
Neural networks can be used to implement anomaly detection, the idea is to construct a neural network that takes in a signal as input and then reconstruct the same signal in it’s output. In this manner the neural network learns features that characterize the signals it is trained on. These features thus define the normal behavior of the signal.
When the network is confronted with an abnormal signal it will not be able to properly reconstruct that signal in its output. This causes a large deviation between the input signal and reconstructed output signal, a term we call the reconstruction error. This reconstruction error indicates abnormal behavior of a signal if applied in real time.
The above text is an English translated version of article: Laan van der T.A. (01-07-2016) De basics van Deep Learning, AG Connect, Number 1
Failure prediction
Although a crash may be preceded by abnormal system behavior, abnormal behavior also occurs on it’s own without the system necessarily failing. For example consider a online web shop during the holiday seasons, input to the system will deviate due to abnormal shopping patterns. In the ideal case we would like to directly couple observed patterns in the data to crashes. This would reduce the false positive rate enormously.
Anomaly detection & StackState
One of the areas StackState is currently focusing on is the application of deep learning in the context of anomaly detection in signals (streams). StackState builds a full-stack observability platform for monitoring your full IT landscape. The aim is to detect problems and gives insight into the root cause of the issue at hand. This way the problem can be resolved faster allowing for shorter downtime.
Disruption of IT environments
The last 3 years has seen a significant change in service, infra and application architectures. This change is driven by micro services, containerization, continuous delivery, DevOps and IoT. All those changes are meant to make the stack more resilient, better scalable and agile. We see that different teams are using different tools to do their job. We also see that new patterns are weaved with old style architectures. This gives a high increase in changes and complexity while the expectation levels of customers are continuously growing. The task to maintain a constantly changing IT stack and act swiftly when problems occur is a daunting one. Especially with the current tool set. Hence the need for a new approach to monitor and manage complex IT environments.
Excited to learn more about AIOps vendor StackState? Request a free guided tour to get a better understanding of our solution.


