Containers are a solution to the problem of how to get software to run reliably when moved from one environment to another. It’s a lightweight virtual machine with a purpose to provide software isolation.
So why are containers such a big deal?
Containers simply make it easier for developers and operators to know that their software will run, no matter where it is deployed. We see companies moving from physical machines, to virtual machines and now to containers. This shift in architecture looks very promising, but in reality you might introduce problems you didn’t see coming.
At some point in time, your containers will break. So it’s better to be prepared. Here are the top 3 challenges you need to know about container monitoring and how to overcome them.
Challenge #1 - Scale
The number of running containers is always greater than the number of servers. When you have 100 servers running, you easily get into thousands of containers. Also the scale and diversity of metrics generated by containers will increase. All the different applications that are running inside your containers can easily generate more than 100 metrics per container per measurement. This means you get into millions of metrics very fast.
Challenge #2 – Behavior
Containers move and change so frequently, that it’s more difficult to keep track of your container landscape and its actual health. Monitoring a service from an individual container only makes sense for long running containers. For short running containers you should be able to see the aggregated metrics for the service they deliver.
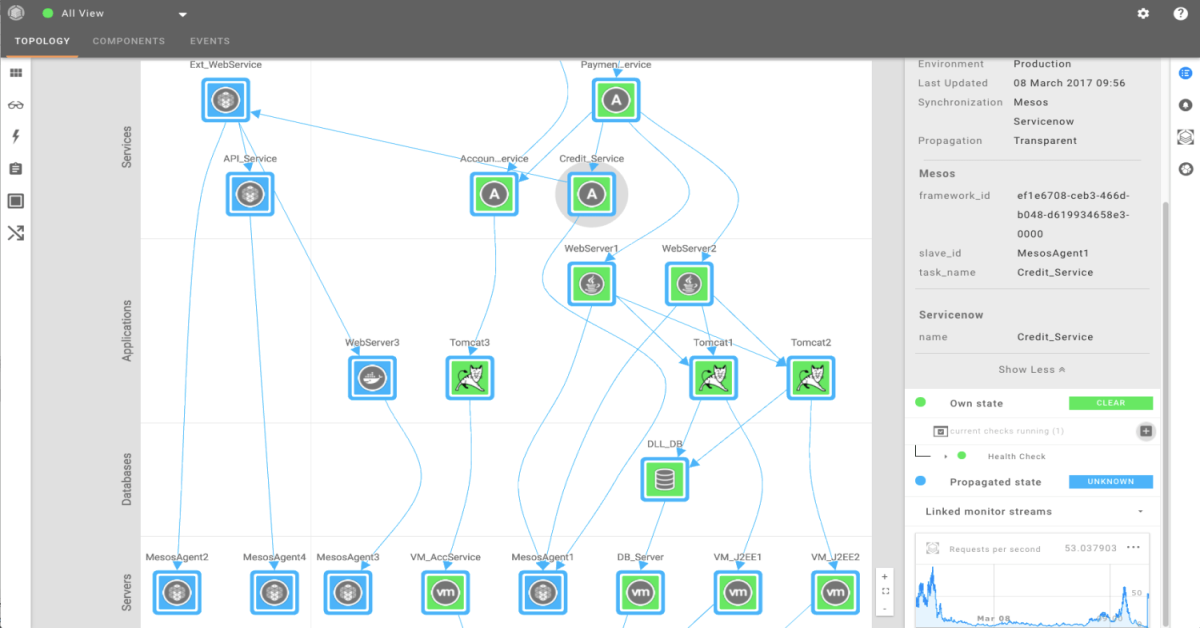
You can imagine that in this kind of dynamic environment, keeping track of and understanding the relations and dependencies between containers and other parts of your landscape is very hard.
Challenge #3 - Tooling
Containers move between hosts and applications where neither application performance tooling nor traditional infrastructure monitoring are effective. This creates a blind spot in your monitoring environment which you have to solve.
Traditional monitoring tools require an agent per VM and now also require an agent per container. This is a wrong approach and will give you too much overhead. Instead, you need to be able to monitor all your containers on one server with one agent.
Metrics you should monitor
As more and more containers surface on test and production networks, you need to know which container metrics and KPIs you should monitor. We’ve selected the 5 most important topics and their metrics that you should monitor:
Hosts (CPU and memory disk)
Orchestrator (services and volumes)
Container (CPU, memory disk and network)
Container internals (applications, database and caching)
Service response times
What to look for in a modern monitoring solution
It's important to use modern monitoring solutions that can cope with the dynamic behavior of containers without making the monitoring process more complex. We've selected a list (yes, we really like lists) of what to look for in a modern monitoring solution. A good solution should be able to give insight into:
How are business services, applications and infrastructure connected to the containers?
Which processes are running on which container?
Which container or service is or could become a bottleneck?
How will changes in your container landscape impact other parts of your infrastructure or the other way around?
Dealing with these container monitoring problems can be challenging, but doable. StackState provides a solution that gives the ability to understand the complexity of your container landscape in real-time with a dependency map instead of a plain table view. All business services, processes and supporting infrastructure components are included in this holistic view. See dependencies and monitor the health of your entire landscape.