Today’s IT organisations use multiple monitoring tools to monitor different parts of the IT landscape. These tools provide visibility into metrics, logs or events, but they don’t provide any details about dependencies and which systems are responsible for causing issues. It is left to the IT operator to map out such dependencies and find the root-cause by assembling teams, processes, tools and piecing together siloed data fragments.
A recent poll at Gartner IOCS Frankfurt (June 5, 2019) highlights this problem:
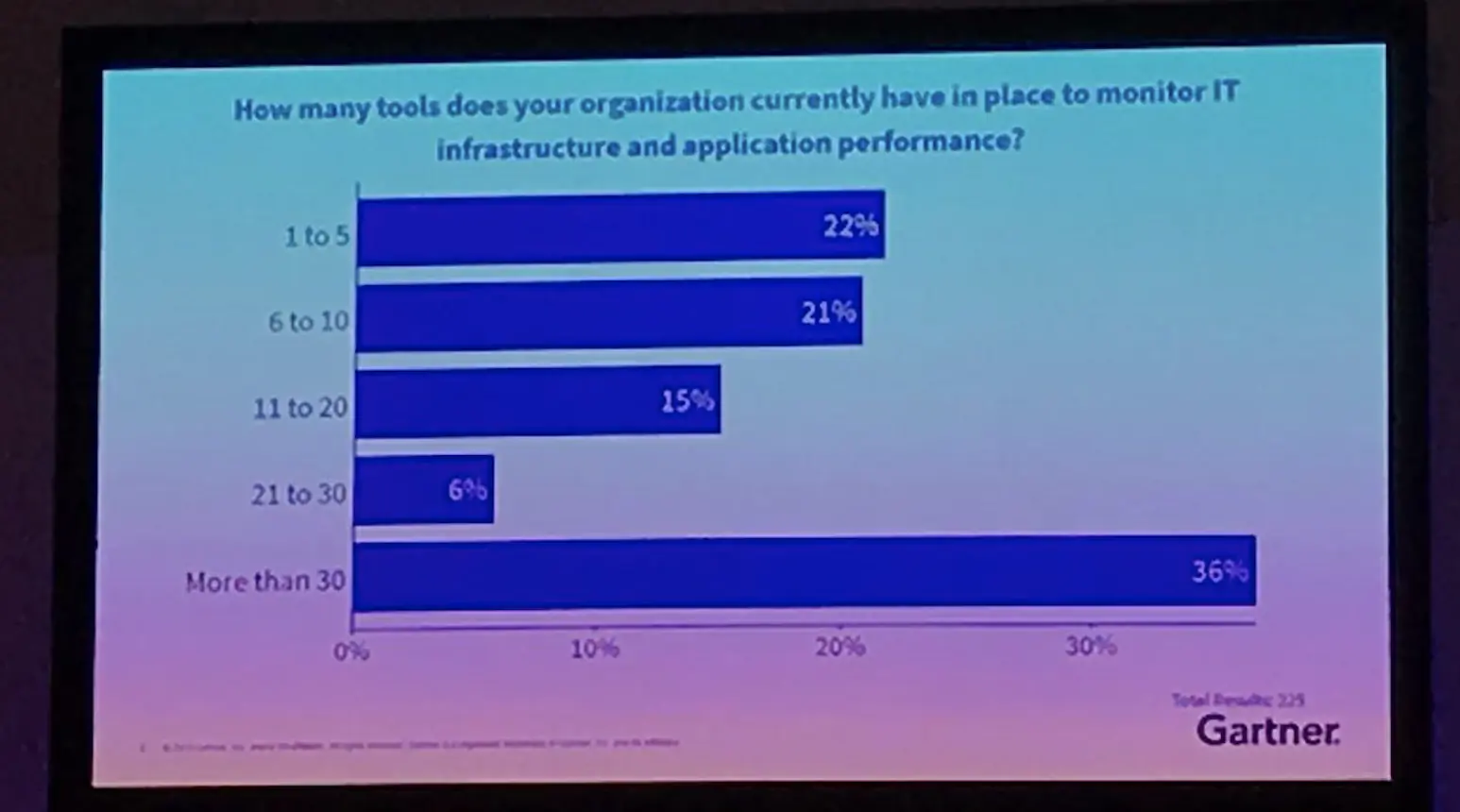
Root cause issues instantly across multiple tools, environments and teams is why we created StackState AIOps and its time travel functionality. We give IT operators full visibility across all their tools and help them to find the cause and business impact of IT issues within seconds.
'Rewind' topology visualizations in time
A year ago, we introduced the time travel capability of StackState. For those who are not familiar with StackState, here’s the concept of our AIOps technology.
StackState combines metrics, logs, events and data beyond typical monitoring data, like Google Analytics, CMDBs, CI/CD tools, service registries, automation and incident management tools. StackState uses this data to learn about dependencies, allowing it to build a real-time topology of IT landscapes. By ‘rewinding’ the topology visualization in time, StackState instantly assist teams in discovering the root cause of incidents and how the impact of these incidents have propagated across on-premise, cloud and hybrid IT landscapes.
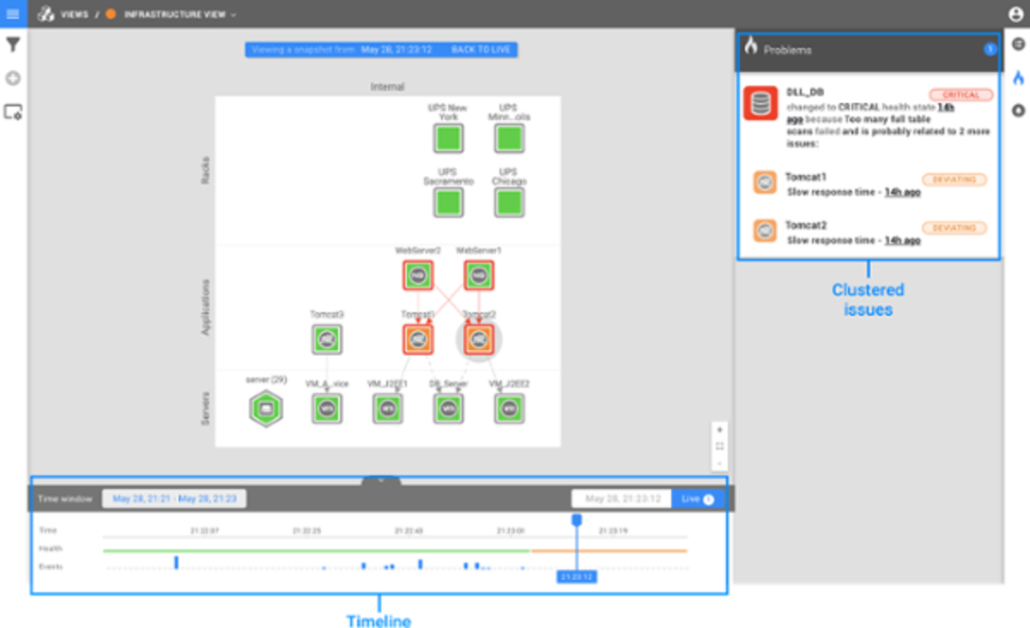
So, StackState knows if and when there is a problem, the contributing factors to that problem and the most likely root cause. Here’s what that looks like in StackState’s user interface:
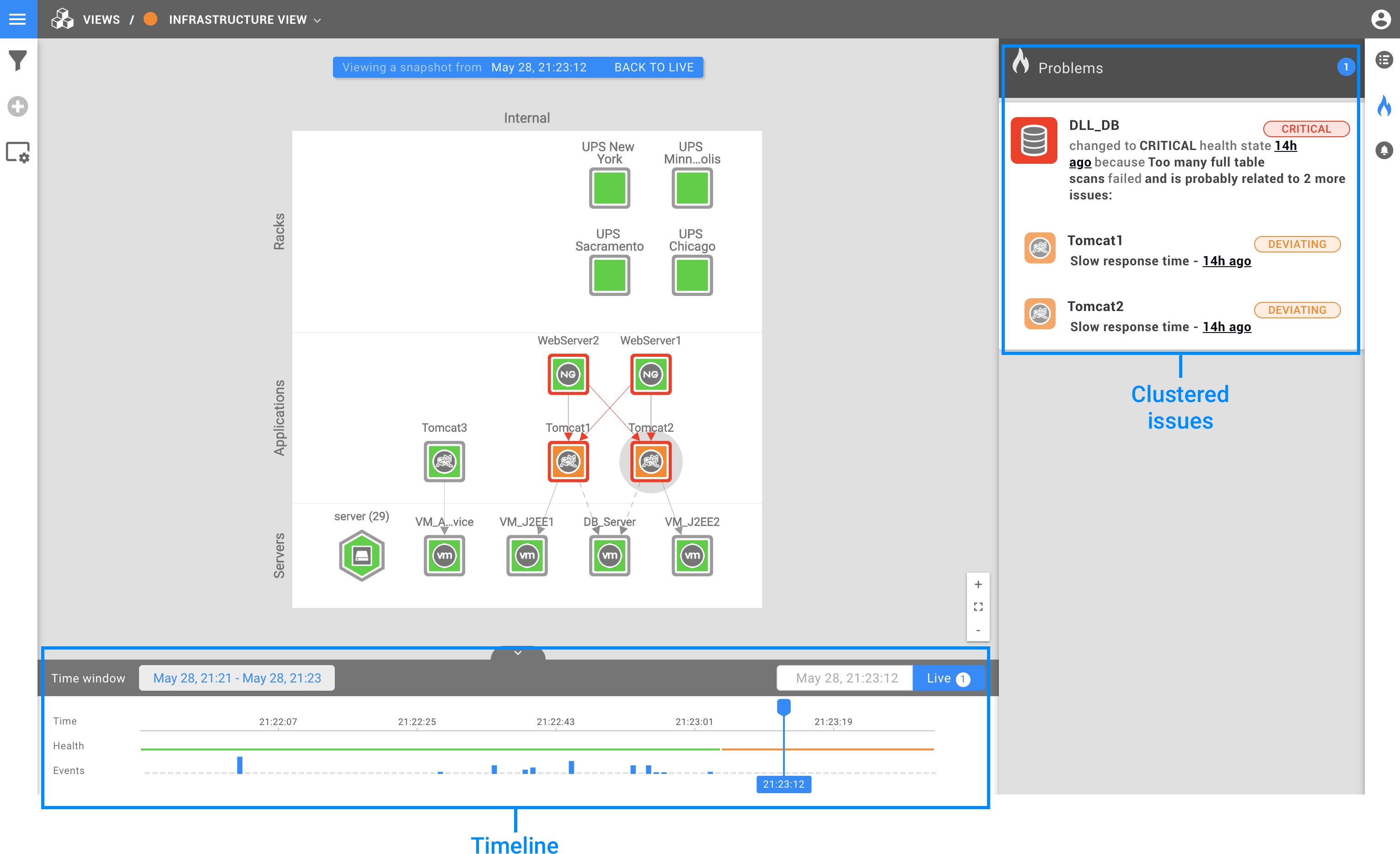
We can see above a topology visualization of an IT environment consisting of racks, servers and applications including their dependencies. StackState keeps a record of the events and health changes that occurred over time. Clicking anywhere on the timeline allows you to travel to that time range, displaying its topology, health state, telemetry AND all related issues.
Now that's root cause analysis on steroids. The benefits for you?
Immediately understand the cause and (business) impact of each and every event over time.
Root-cause issues by a single person or team. Say goodbye to war rooms and save valuable time.
Increase availability, shorten your MTTR and deliver better customer experiences.
Immediately understand what's going on
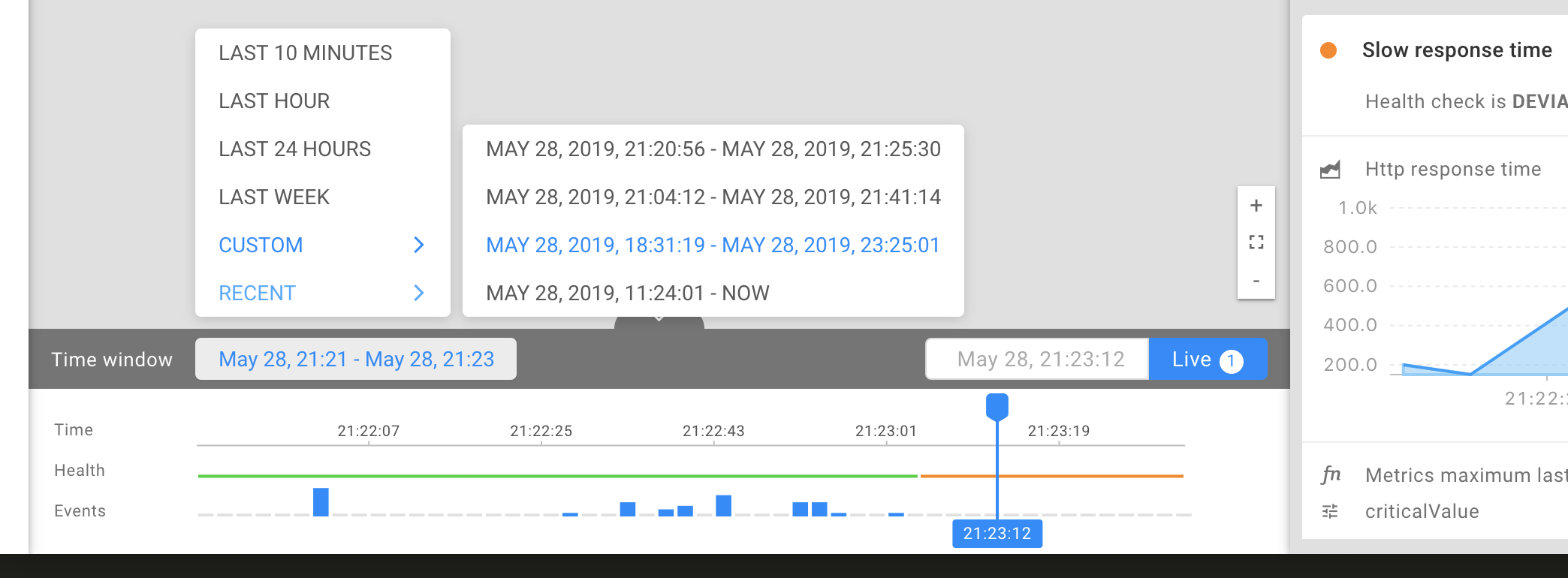
We've also made it easier to select a more specific time range. Users can select several time windows such as last week, last 24 hours, last hour, last 10 minutes or create a custom time window. In addition to this, the timeline displays the health state and the amount of events that happened so users immediately understand what's going on and can quickly drill down to the root cause.
By introducing the new time travel capability of StackState, we've further improved the strengths of our AIOps platform. Enterprises around the world such as IBM, Nationale Nederlanden and Fujitsu are using StackState to save time, fix issues faster and deliver better customer experiences.
If you would like to learn how StackState accelerates your MTTD and MTTR, feel free to request a guided tour of our AIOps solution .


