
In today's cloud-native landscapes, observability is more than a buzzword; it's a critical element for software development teams looking to master the complexities of modern environments like Kubernetes.
There’s a multi-faceted nature to observability with all its various levels and dimensions — from basic metrics to comprehensive business insights. It’s complex and can continue indefinitely…if you let it.
So what exactly does observability entail, and when is it “good enough” for DevOps engineers, developers and business leaders looking to empower teams to operate more efficiently and deliver a superior customer experience?
When is 'Enough' Observability Really Enough?
In interactions with current and prospective customers, we often address the question of how to know when you've achieved sufficient observability and can confidently move forward. The general consensus of a seemingly comprehensive solution often leans towards using metric-oriented dashboards supplemented by log analysis tools. From a team perspective, arriving at that initial conclusion is easy.
However, a critical question persists: Are your software development teams truly empowered to effectively operate and troubleshoot applications running on Kubernetes?
Let’s Draw A Line In The Sand
Before we dive into additional considerations that often go unnoticed, let's outline what we already know. In an earlier post on this subject, Guided Kubernetes Troubleshooting: How To Reduce Toil for Dev Teams , I covered why a dashboard-oriented approach is insufficient for running your apps effectively on Kubernetes. Still, diagnosing issues can be laborious and time-consuming, and maintaining system reliability is challenging, so I outlined six engineering challenges that need to be solved before any troubleshooting can begin. These are:
Kubernetes environment complexity: Coping with intricate K8s systems and tools.
Too much change: Challenges in tracking constant system variances.
Lack of knowledge: Difficulty gathering and interpreting data, especially if unfamiliar with K8s.
Too much context switching: Fragmented issue-solving across multiple tools.
Lack of historical data: An absence of history will impact issue analysis.
Cost of engineering time and toil: Maintaining open-source observability is labor-intensive.
These challenges can result in prolonged troubleshooting, impacting the customer experience and creating inefficiencies within engineering teams. But the real question is — and this is where many troubleshooting solutions still fall short — whether or not this is enough to deliver exceptional customer experiences.
You have to look past the small details to see the "big picture," and while understanding the immediate technical challenges is crucial, broader aspects warrant our attention.
Facing similar challenges with observability? Click here to see how StackState can help.
Beyond Kubernetes: Taking Other Tech into Account
It's rare that an application would rely solely on Kubernetes resources. Instead, they'll often incorporate cloud-native components from AWS, GCP, Azure or even on-premises databases. This is because maintaining a narrow focus can limit insights into the bigger picture. For example, how would you troubleshoot slow response times if the root cause lies in database queries?
Generally, three additional "big picture" angles need consideration to ensure your business stakes are covered while utilizing cloud-native technologies. These elements will allow you to address a broader set of technologies:
Consolidate all data into one location, where metrics are seamlessly integrated into unified and related dashboards that are easy to navigate.
Build a rich dependency map to visualize and navigate dependencies, which is particularly powerful when you need to understand the impact of an issue.
Equip teams with out-of-the-box dashboards that are resource-specific yet standardized across the organization. Experts can further fine-tune these to assist colleagues and facilitate rapid knowledge sharing.
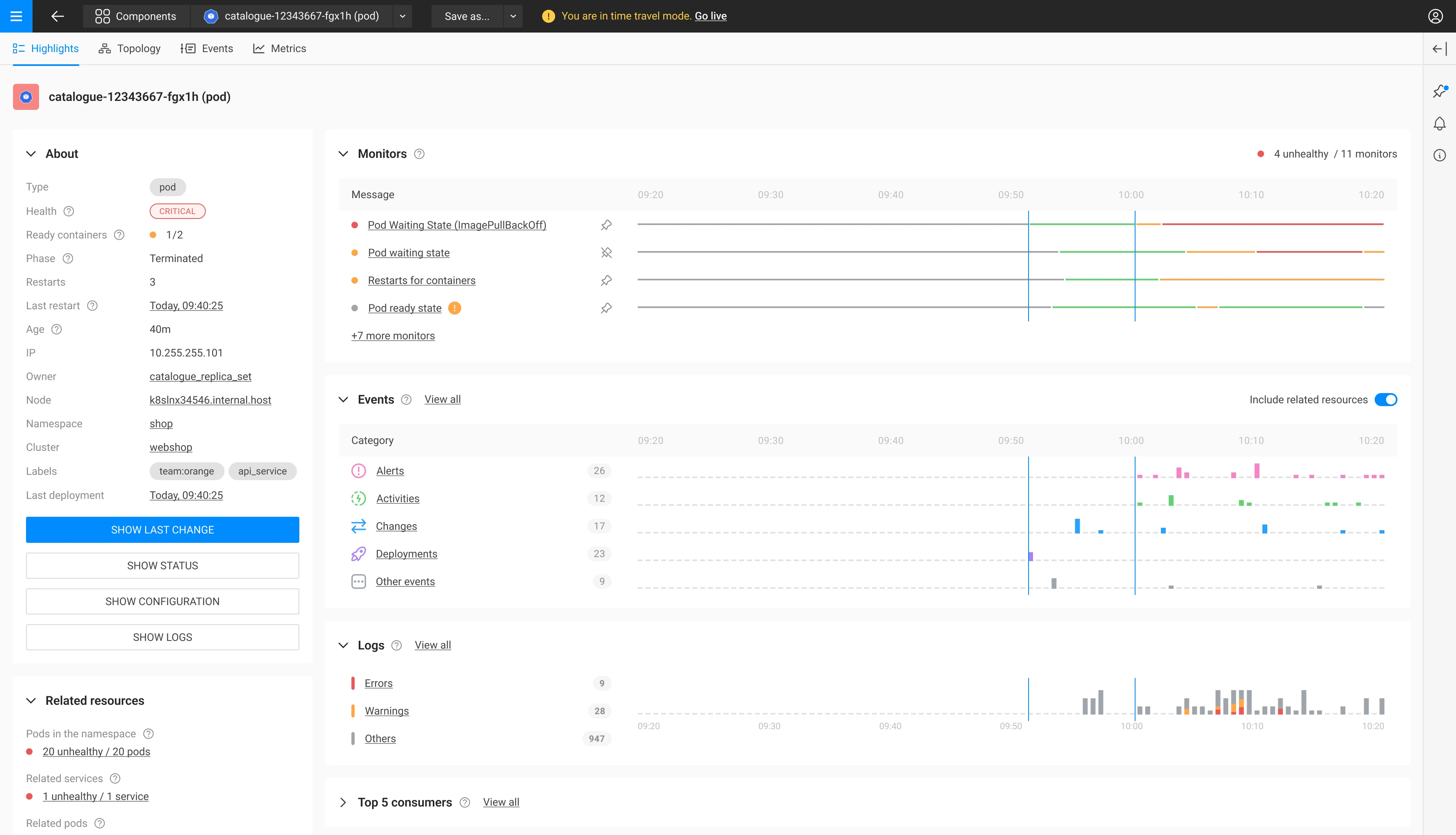
This is an example of a pod highlight page in our playground. Want to explore the product yourself? Click here.
Beyond Software Developers: Catering to Other Roles
Going beyond Kubernetes, let's not forget the people aspect in our observability strategy.
Getting things done efficiently is a team effort. But pointing fingers when things go wrong only slows down remediation. Better to opt for a tool that can be easily used and adapted by everyone on the team, regardless of their roles or expertise. Here are some important factors to take into account:
Ensure secure access to the required for effective troubleshooting.
Utilize dashboards that are simple enough to be used by those with limited Kubernetes background yet rich enough to meet your experts' needs.
Adopt a solution that fosters close collaboration between team members, such as the ability to share dashboards or specific moments in time.
Beyond Resources and Application Level: Considering the End-to-End Picture
Having addressed the importance of role-specific tools, let's extend our focus to an even bigger picture — the end-to-end business service chain.
While it's common knowledge that monitoring component behavior is crucial — we’ll call this level one — many tend to stop at this point in their observability strategy. At StackState, we consider there to be two more levels.
The second level focuses on your business applications, the backbone of your operations. So, why is this categorization so significant?
Issue impact: When a glitch occurs in one part of your business app, it can have a domino effect. Grouping them allows you to address critical alerts first.
SLIs and SLOs: Setting these performance indicators and objectives at the application level is crucial for aligning with business needs.
Effective communication: Collaborating effectively with business representatives requires using terminology and metrics that resonate with their understanding and priorities.
Simplicity and clarity: Maintaining an organized and understandable space that consolidates essential metrics, alerts, dependencies and actions is essential for efficient day-to-day operations.
A third level involves examining the end-to-end chain of your business services. Understanding the complexity of this "beast" is extremely powerful, as it allows you to:
Quickly pinpoint the root cause and scope of significant outages.
Minimize the disruption caused by involving the wrong engineers when problems occur.
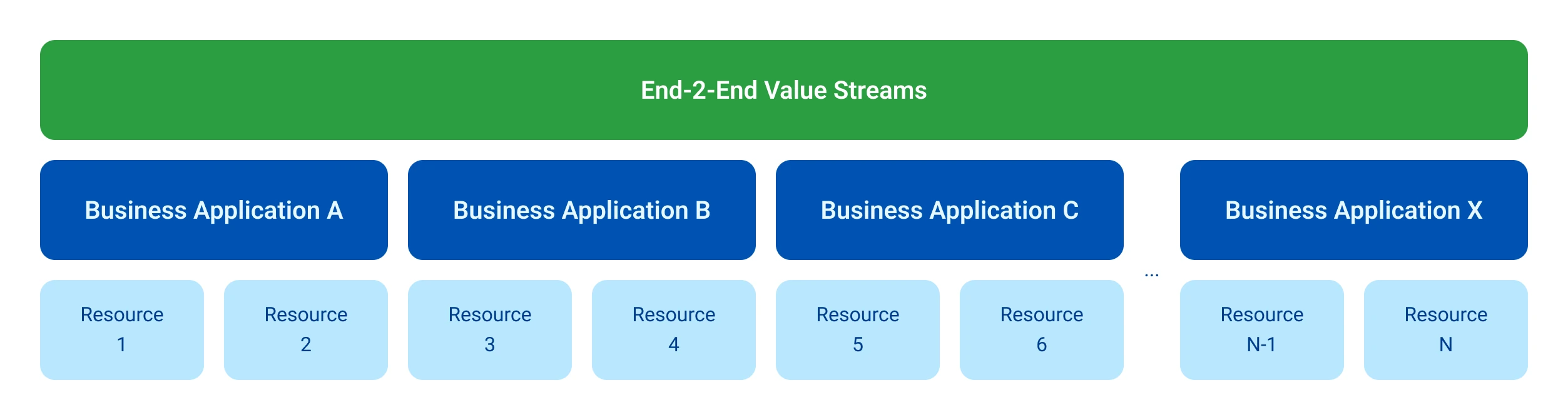
Having a complete understanding of your business services is not just a bonus; it's essential for efficient operations. Next, let's explore how StackState fits into this complex puzzle.
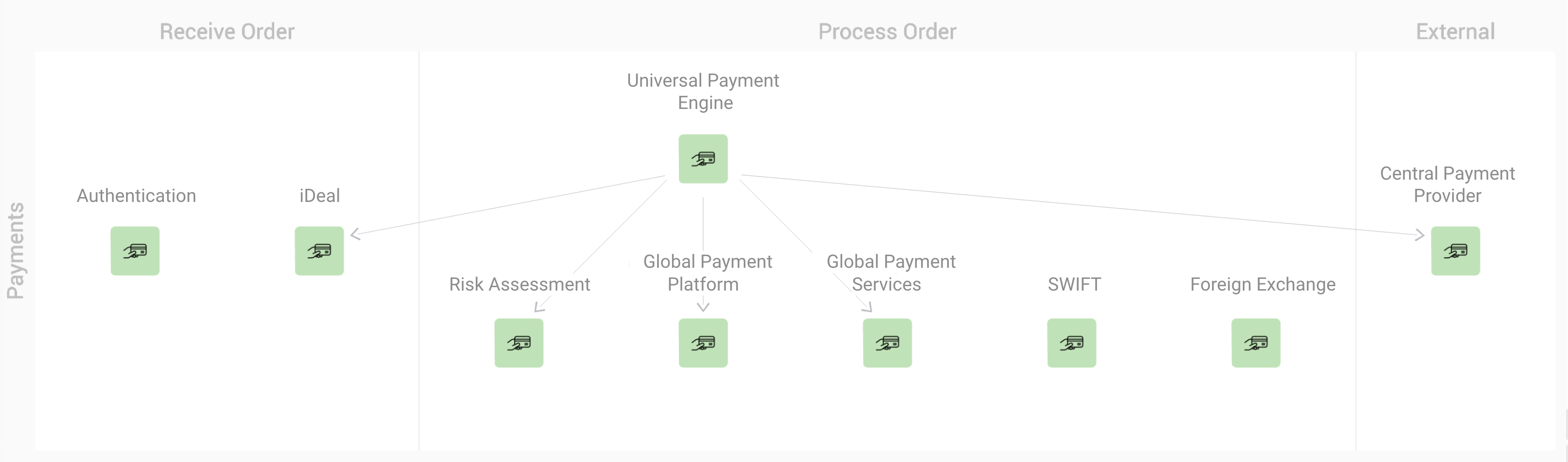
Interested in driving more business value with better observability? Learn more about StackState’s solutions.
How StackState Can Help
StackState is designed to empower teams by simplifying the complex world of IT operations and observability. Our full stack observability platform offers a unified UI that seamlessly integrates with your existing tools, providing a comprehensive view across different levels of your architecture. From deep technical resources to business applications and all the way up the value stream, StackState streamlines data navigation. This means less time troubleshooting and more time driving business value.
So, how does StackState tackle these challenges and considerations? Here's the breakdown:
We offer a range of pre-built dashboards, monitors and best practices.
With intelligent grouping and comprehensive topology mapping, we effortlessly bring any combination of resources together.
We excel in large topology visualization, particularly when developing an observability strategy across multiple teams.
By addressing these elements head-on, StackState is dedicated to delivering a holistic approach to observability. Our goal is to empower not only technical excellence but also to drive tangible business value.
With these strategies in place, you won't just optimize individual teams—you'll transform your entire IT operations for success. But don’t just take our word for it; experience the power of StackState for yourself. Sign up for a free trial .


