
In one of our latest posts, StackState Co-Founder Mark Bakker described how eBPF revolutionizes observability and how StackState’s agents rely heavily on eBPF to capture and analyze the data moving through your cluster.
Today, we’re looking at an example where our eBPF code failed and — by diving deep into the intricacies of eBPF implementation in the Linux kernel — share the tale of how we fixed it using even more eBPF. To follow along, you’ll need some working knowledge of eBPF, which you can acquire from Mark’s post linked above and from ebpf.io .
How did we find the failure?
StackState not only develops a cluster monitoring solution for customers to use, we also use it ourselves. As part of our commitment to quality, we run pre-release versions of our components on our own infrastructure, predominantly hosted on Google Cloud and AWS. We operate a combination of custom Ubuntu-based nodes and default nodes, which run Google’s Container-optimized OS (COS) on our Google Kubernetes Engine (GKE) clusters.
One of the most important parts of our agent is the eBPF-based HTTP probe. This component allows you to use StackState for troubleshooting HTTP error codes, even for TLS connections, without any additional instrumentation from the endpoints. The probe is loaded into the kernel when the StackState agent starts. However, after an update to our cluster nodes, the loading failed on some of them, while it still worked fine on others.
After some quick investigation, we observed the probe consistently failing to load on COS, whereas it would work fine on our Ubuntu machines. Initially, we suspected a kernel compatibility issue. Then, we encountered the error below, which appears to indicate an error in the verification process.
2023-12-29 15:46:02 ERROR (tracer.go:828) -
usm initialization failed:
could not initialize USM:
error initializing ebpf program:
runtime compilation failed:
verifier error loading eBPF programs:
program socket__http_filter:
load program: operation not supported
[...]eBPF verification and JIT compilation
An eBPF program is specified using a custom, reduced instruction set . When an eBPF program is loaded into the kernel using the bpf() syscall , the verifier ensures that it is safe to run within kernel space. Among other things, the verifier checks that the program terminates within a bounded number of CPU cycles and does not access arbitrary memory addresses (see the docs ).
Originally, the bytecode would be interpreted in the kernel after verification. However, for performance reasons, recent kernels will instead compile the verified code into native machine code first. This just-in-time compilation step is separate from the initial C → BPF bytecode compilation that is done in user-space to generate the eBPF program.
For debugging, the bpf() syscall takes a buffer in user-space as an argument and fills it with the verifier’s log output. However, it's worth noting that this log does not include any messages from the JIT compiler.
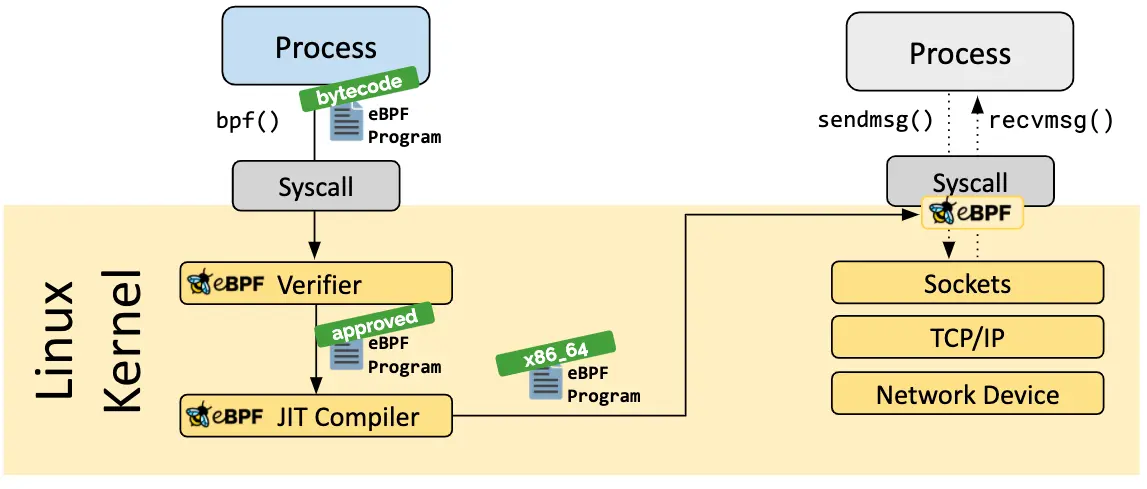
Down the rabbit hole
So, why was our code deemed safe on Ubuntu but not on COS? When we examined the debug messages from the verifier, they only contained tracing messages and statistics, without any actual error message, even on COS-based nodes.
Perhaps the issue lies elsewhere, outside the verifier. In the kernel, the verifier and the JIT compiler are just two functions that our bytecode is being passed to. So, we decided to use another eBPF probe to take a closer look at these functions while attempting to load our HTTP probe. eBPF tracepoints allow us to do exactly that and bpftrace is a great tool for creating these one-off debugging utilities.
By instrumenting the function calls inside the kernel, we could go beyond merely interpreting the syscall's return codes. Our utility program leverages tracepoints to explore the internal operations of the verifier and JIT compiler. The following code snippet demonstrates how we tracked our original probe's journey through the kernel: from the moment of its loading, through the bpf_check function overseeing verification, and finally to its interaction with the JIT compiler, typically obscured from user-space programs.
// Save as bpf_bpf.bt
// Call sudo ./bpftrace bpf_bpf.bt// Executed when we enter the bpf() syscall
tracepoint:syscalls:sys_enter_bpf {
if (args.cmd == 5) {
printf("%d:%d: bpf() entering, loading prog %s\n", pid, tid, args.uattr->prog_name)
}
}
// Executed right before bpf_check() returns
kretprobe:bpf_check {
printf("%d:%d: Verification error: %d\n", pid, tid, retval)
}
// Executed right before bpf_int_jit_compile() returns
kretprobe:bpf_int_jit_compile {
printf("%d:%d: JIT: Done, compiled?: %d\n", pid, tid, ((struct bpf_prog *) retval)->jited)
}
// Executed right before the bpf() syscall returns
tracepoint:syscalls:sys_exit_bpf {
if (args.ret < 0) {
printf("%d:%d: bpf() returning, ret: %d\n", pid, tid, args.ret)
}
}Using bpftrace with the script above and watching the output scroll by, it will look like the snippet given below. The syscall is returning -524, which is the errno value for the “operation not supported” error we saw earlier. In addition, we see the return values of the verification step (bpf_check) and the jit compilation (bpf_int_jit_compile).
2229:2236: bpf() entering, loading prog socket__http_fi
2229:2236: Verification error: 0 // No error
2229:2236: JIT: Done, compiled?: 0 // 0 == False
2229:2236: bpf() returning, ret: -524Zero indicates success for the bpf_check function, so there is actually no error in the verification step. But the JIT compiler is unable to get our code compiled (0 means false here). So our valid code just cannot be translated to executable machine code by the kernel’s JIT compiler.
This is a huge step forward in our understanding of the error. Even though the error log emitted a 'verifier error', the verification actually succeeds, and we are looking at a compilation error.
Curiouser and curiouser
At this point, we know why our probe cannot be loaded, but two questions remain:
Why does it work on the Ubuntu machines?
What can we do to fix this?
To answer the first question, we first look for any differences in the setup of our nodes. A good starting point is to examine any BPF-related system configuration using sysctl -a | grep bpf. Here, we find an interesting difference: COS sets net.core.bpf_jit_harden to 2 (enabled for all users), whereas Ubuntu has it set to 0 (disabled).
Following our hunch, and equipped with root rights, we can enable the hardened compilation on Ubuntu using just echo 2 > /proc/sys/net/core/bpf_jit_harden. Indeed, we now see the same failure as on COS.
> Aside: What is hardening?
The details of how the hardened compiler differs from the regular one are beyond the scope of this blog post, but in this particular case, the translated BPF byte code of the hardened version contained more instructions than the regular version due to constant blinding .
The compiler added additional instructions between a jump command and its target, rendering it unable to rewrite the jump offset because the size of the jump was now out of bounds for the 16-bit argument of the instruction. For those interested in further details, refer to this thread in the Linux Kernel BPF mailing list.
The fix
The root cause investigation on the Ubuntu machine directly results in a fix for the COS-based ones: We temporarily disable the hardening there with echo 0 > /proc/sys/net/core/bpf_jit_harden, re-run the bpftrace script and the process agent, and get:
2826:2828: bpf() entering, loading prog socket__http_fi
2826:2828: Check: 0
2826:2828: JIT: Done, compiled?: 1Success! Our probe loads fine and runs without any issues
In summary:
The eBPF program failed to load on Google's Container-optimized OS (COS) due to a compilation error, not a verification issue.
The issue was traced to the JIT compiler, which was unable to compile the code.
Disabling the hardened compilation on COS resolved the problem, allowing the eBPF program to load and run successfully.
If you remember that the eBPF code was originally interpreted in the kernel, you might wonder why we cannot just skip the compilation step that's causing the error. The Linux kernel actually contains a fallback for cases like this. In situations where the code is safe to run but cannot be compiled to native code, this fallback mechanism comes into play.
In this fallback mode, the BPF bytecode is interpreted instead of compiled. However, all recent Linux distributions disable this path by setting CONFIG_BPF_JIT_ALWAYS_ON. A program failing to be JIT-compiled cannot be loaded into such a system. In contrast to the bpf_jit_harden control, CONFIG_BPF_JIT_ALWAYS_ON is a compiler flag and cannot be disabled at run-time.
> Aside: The final fix
If you care about security at all, you probably have some reservations about us disabling the hardened compiler to work around our issue. You are right: The hardened eBPF compiler should be able to compile any verified eBPF program, and kernel developers are working on getting this fixed.
Currently, the issue can only be solved by compiling our probe’s C source code with the -mcpu=v4 flag , which will cause the compiler to emit a BPF_JMP32 instead of a regular BPF_JMP. This takes a 32-bit argument and can therefore accommodate the additional instructions inserted by the constant blinding step. Sadly, the resulting byte code is only supported on kernels version 6.6 and later, while we try to support kernels down to version 5.4.
So the real fix is likely to replace the BPF_JMP with a BPF_JMP32 in the hardening step, a solution proposed by Eduard Zingerman on the mailing list, but not yet implemented in the kernel.
Until this fix lands in the kernel and becomes widely adopted in our customers' installations, we disable the hardened compiler for the probe's loading and immediately enable it again afterward.


