
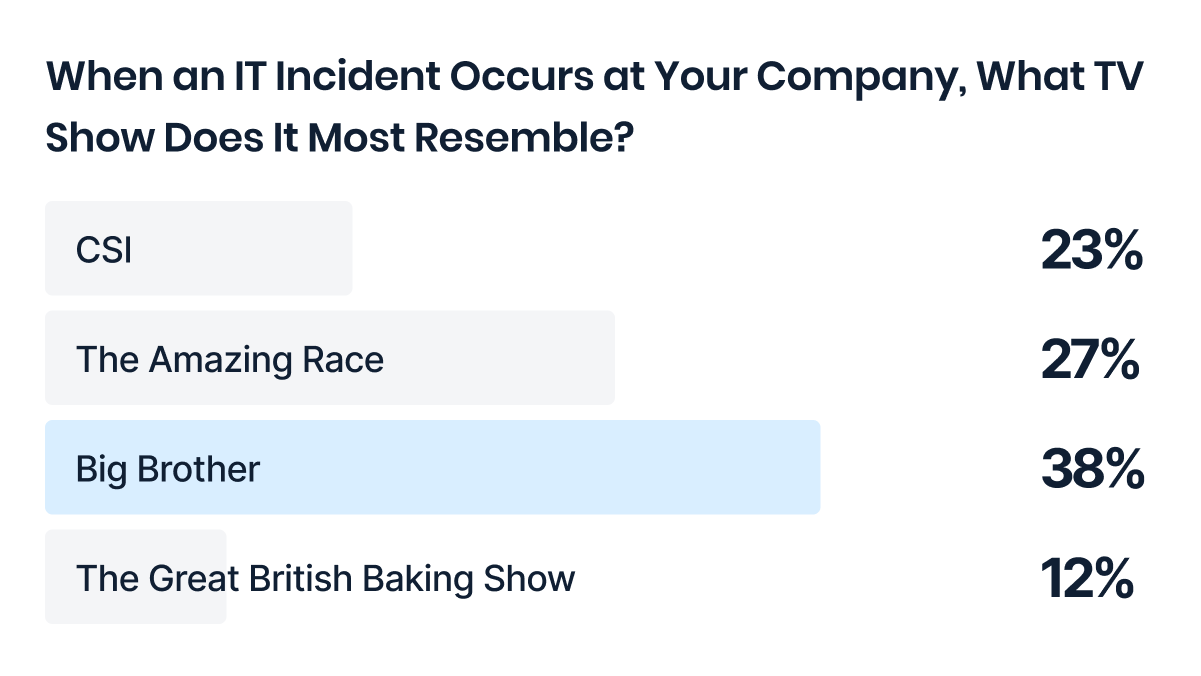
(Author's note: We took the poll results and likened an ideal incident resolution process to CSI.)
Big Brother: We monitor everything, but somehow shenanigans still occurs
Getting almost half the votes, our poll showed that most respondents liken IT incidents to an episode of Big Brother. Your IT environment is highly monitored, yet incidents still seem to slip through the cracks.
When this happens, how does your team react? If you're using topology-powered observability, you won't get voted out at the end of the episode. Instead, you'll save valuable time and energy you'd otherwise spend while hunting for the root cause. We know that even with 24-hour monitoring, getting the big picture can be hard. Your IT team can get the coveted "Head of Household" with topology-powered
observability across all your IT environments to tackle IT incident prevention.
CSI IT: Get forensic about ID’ing the problem and "who dunnit"
Does every IT incident turn into an episode of CSI, with your team pulling out the magnifying glass to find key clues and solve the mystery? With the Telemetry Perspective, your team can get a closer look at the evidence to see the critical metrics for an unhealthy component.
Then, trace your steps back through all points of the crime with time-traveling topology for greater visibility into what changed and when.
The amazing race: The clock is ticking, fix the problem before users notice
Tick tock...is your team feeling the pressure of either finding the root cause as quickly as possible or risking being "eliminated"? If it feels like you're making a mad dash toward finding the solution but there's no end in sight, you need a better way.
You can resolve incidents quickly with topology-powered observability because it helps you relate changes with incidents, giving you insights into your entire IT landscape. You can now solve your IT incidents faster and reach the finish line before your time is up.
The Great British Baking Show: The right recipe for repairs
Are you lucky enough to resemble an episode of the Great British Baking Show? If you've got the ingredients - er, tools - already implemented that work well and impress the judges, then you may find yourself crowned the winner.
What's the winning recipe? That would be a delicacy of StackState’s topology-powered observability, bringing dependency and relationship analysis, change and incident mapping, and autonomous anomaly detection to the table. This enables you to speed up remediation by getting to the root cause faster. And that’s Paul Hollywood-handshake worthy.
Whatever you do, don't be The Twilight Zone
Whichever show in the polling question your company most resembles, consider yourself lucky that you're not in an episode of The Twilight Zone. If you were, we cannot even imagine the twists and turns that IT incident approach might take! You can ensure your next IT problem “episode” is less cringe-worthy by relating changes to incidents via topology.
Here's the bottom line—while all companies running software to support their business-critical functions experience problems and outages, not all companies experience and respond to IT incidents in the same way. Using StackState, you can prevent outages within your company and improve your resolution time.
Get in touch with us today to schedule your free guided demo and start exploring StackState's topology-powered observability.


