The future of IT Operations: receive post-mortem reports for predicted incidents
Did you ever see that movie Minority Report? Where Tom Cruise arrests would-be criminals before they commit murder by watching future events unfold through a process called pre-cognition. Pretty cool, but obviously science fiction and wrought with ethical concerns. What if I told you that in the near future something like this could be possible for IT incidents though? Enter Automated Pre-Mortem Analysis!
Automated Pre-Mortem Analysis, or APMA for short, aims to generate as much contextual information as needed in order to prevent a predicted incident and/or its consequences as early as possible. By way of artificial intelligence, APMA combines information for a predicted incident and its consequences from multiple sources into a post-mortem-like report before the incident impacts your business.
An example to illustrate
Here is a simplified post-mortem report inspired by true events at a well-known bank.
Post-mortem report #492: Credit Rating Service outage
Date: 23-Oct-2018 13:43
Summary: After a bugfix release to the Credit Rating System (CRS). The CRS became progressively slower until 7 hours later CRS stopped working causing downtime on the online loan and credit card services.
Impact:
2+ hours of downtime on the online services related to the requesting of loans and the extension of credit cards. Approximate revenue loss estimated between $95k and $120k.
Several other offline processes, most notably the mortgage enrichment process, were delayed in their processing. No revenue loss. Slight impact on their SLAs.
Root cause:
What was supposed to be a small bugfix caused a memory leak in the CRS. The bugfix contained a minor upgrade of a library, which introduced the memory leak.
Trigger:
Bugfix release to the CRS: version upgrade 2.14 to 2.15 (#CRS-5345).
Detection:
Two alerts were triggered by monitoring on the response times of the loan request and credit card extension services that depend on the CRS.
The causing component of the issue was unclear until the monitoring on the CRS triggered an alert.
Resolution:
All CRS processes were restarted, but a connection flood coming from an offline mortgage enrichment process made it impossible for the CRS to start. The mortgage enrichment process had to be temporarily stopped, after which the CRS processes were able to resume normal operations.
Later that day the bug fix was found to be the root cause. A new fix was deployed and no more memory leakage was observed.
Timeline on 19-Oct-2018:
10:01: Bugfix deployed to CRS
17.06: Alert triggered by Loan Request Service: slow response time.
17.14: Alert triggered by Credit Card Extension Service: slow response time.
17.44: Alert triggered by CRS monitoring: out of memory exceptions.
18.01: CRS restarted, but remains unresponsive.
18.25: Determined that Mortgage Enrichment connection flood prevents CRS from restarting.
18.51: CRS and Mortgage Enrichment restarted in tandem.
18.53: CRS and Mortgage Enrichment 100% operational.
Lessons learned / Actions taken
Note: a list of lesson learned and resulting actions should be a part of every post-mortem, but is irrelevant to this blog
Alerting problems
As you sit back in your chair and relax, please take some time to imagine the point of view of the engineers tasked with this mess. The afternoon has passed and you’re hoping to get some work finished before the end of the day, but then:
17:06 Alert – Loan Request Service - Response time exceeds threshold (>2s).
There are two major problems with these types of alerts:
Lack of information:
The root cause(s) of the problem is missing. You may spend hours looking for it.
The impact of the problem is missing. It may be extremely important or it may be a glitch.
It is unclear what other events/alerts are related to the problem. The problem may have caused an alert storm and multiple people may already be working on the same issue.
As a result of the above it is also unclear who should be notified/involved.
The alert comes too late, especially given the lack of actionable information.
Unfortunately this is still the state of monitoring/alerting at most large enterprises. With this type of information can we expect a quick and effective response?
Artificial Intelligence to the rescue!?
We are seeing a lot of emphasis on predictive analytics in the monitoring space, but the low-level approach that many take does not solve these problems.
For example, here is how the response time of the loan service looked like during the incident:
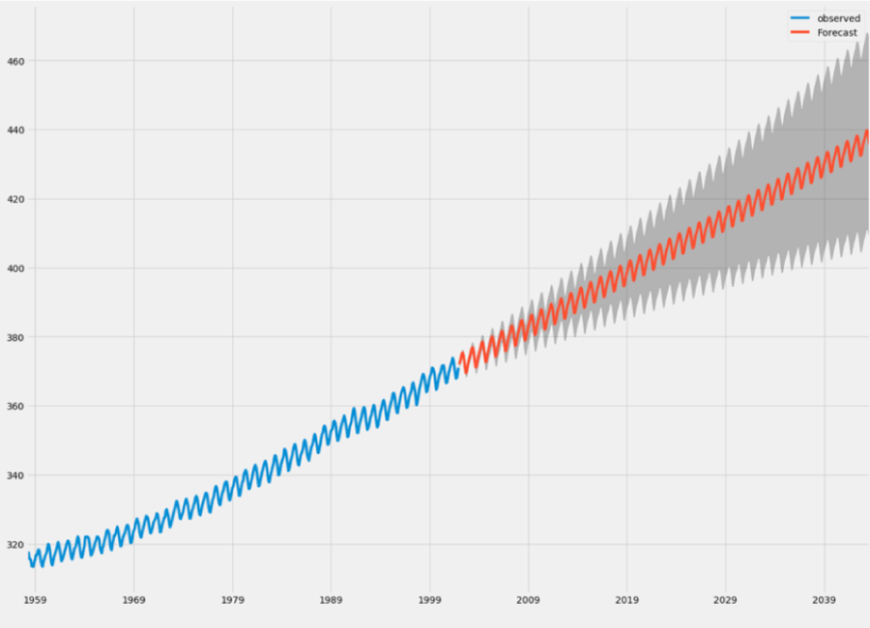
By looking at historical data (the blue line) we can build up a predictive model. The extrapolations that we make based on these models (the red line) become less accurate as they move farther into the future (hence the widening gray band). If a significant part of the predicted model’s distribution exceeds some critical threshold many monitoring products can be configured to give you an early warning:
15:05 Alert – Loan Request Service - Response time predicted to exceed threshold (>2s) at 17:09 (probability 95%).
In terms of the level of information there is no change, but now at least we have a two-hour head start. This might not actually be an improvement though. We have effectively traded the problem of the alert coming too late for potential false positives. In other words, though this prediction might help prevent a problem, it could also be a problem itself. It could be wrong and a waste of precious time.
Perhaps we can call this an improvement, but I believe we should raise the bar.
A smarter AI
Automated Pre-Mortem Analysis is a way to solve both these problems in one stroke, while limiting the problem of false positives.
APMA typically starts with the same types of predictive analytics, but continues from there by analyzing multiple sources of data using multiple AI techniques like automated root cause analysis, impact analysis, machine learning techniques, etc. (this is the content for a future blog). Because the same problem is approached from different angles and there are multiple sources of evidence it is also a great way to lower the chance of false positives.
Here is the APMA report of the above incident. Remember, this report is generated approximately 2 hours before the trouble starts.
Pre-mortem: Possible outage Loan Request Service & Credit Card Extension Service
Report date: 15:05
Probable Impact:
Unresponsiveness / outage:
Loan Request Service unresponsive. Correct? 👍 👎
Credit Card Extension Service unresponsive. Correct? 👍 👎
Unknown impact expected on:
Mortgage Enrichment Process. Correct? 👍 👎
Account Service. Correct? 👍 👎
5 more…
Probable Root Cause:
Components: CRS Service: CRS-1, CRS-2, CRS-3. Correct? 👍 👎
Stream: ‘Memory usage’ CRS increasing. Correct? 👍 👎
Stream: ‘GC pauses’ increasing. Correct? 👍 👎
Probable triggers:
#CRS-5345 10:01: Release 2.14 to 2.15. Correct? 👍 👎
Detection:
Loan Request Service - Response time predicted to exceed threshold (>2s) at 17:09 (probability 95%). Correct? 👍 👎
Credit card extension service - Response time predicted to exceed threshold (>2s) at 17:20 (probability 89%). Correct? 👍 👎
Timeline:
10:01 #CRS-5345: Release 2.14 to 2.15
15:05 APMA Report generated
15:09 Now
17:09 Predicted critical status: response time on loan service critical status
17:20 Predicted critical status: response time credit card limit extension service
Bam! With this report you immediately have a good understanding of what is going on. Multiple predictions have lowered the chance of this being a false positive and the importance of this report is clear from the predicted impact.
Like with automated root cause analysis, a pre-mortem report will be an approximation based on what the machine knows and can infer. Out-of-the-box pre-mortem reports can be pretty good approximations, but by users providing feedback () on the correctness of the reported details it will get even better. A pre-mortem report resembles a post-mortem report, but of course it will be some time before the first pre-mortem report passes the Turing test.
Nevertheless, imagine getting this report on the day this was about to transpire, hours before disaster strikes. You’d easily save the day and go home, on time, feeling like Tom Cruise. That is what Automated Pre-Mortem Analysis is all about!
More to come..
I have been working on StackState, a next-generation monitoring and AIOps platform that makes this possible. We have all the puzzle pieces in place: the math, the algorithms and the data. I will be documenting our journey to a fully working APMA solution over the coming period. More details on APMA will follow.


