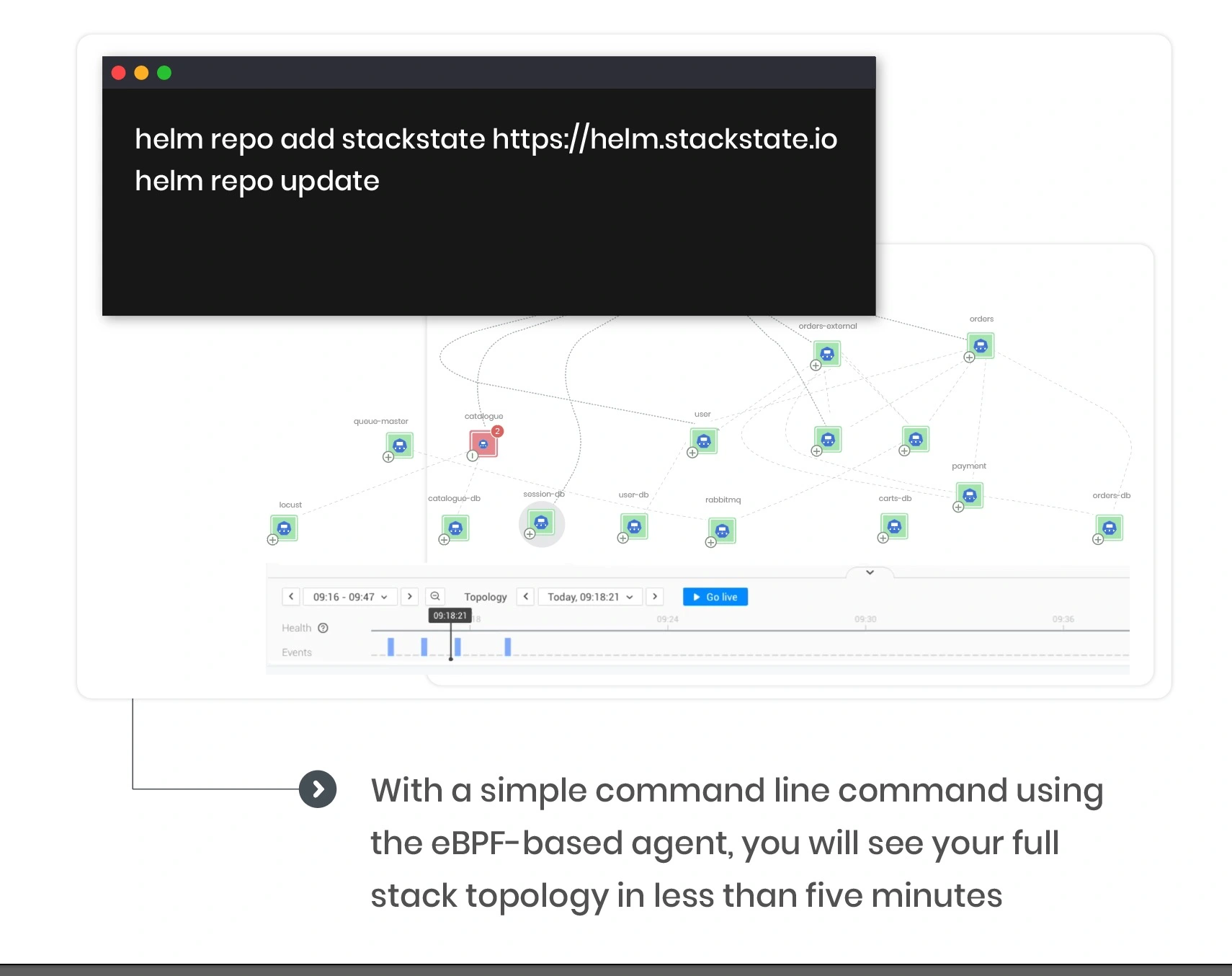
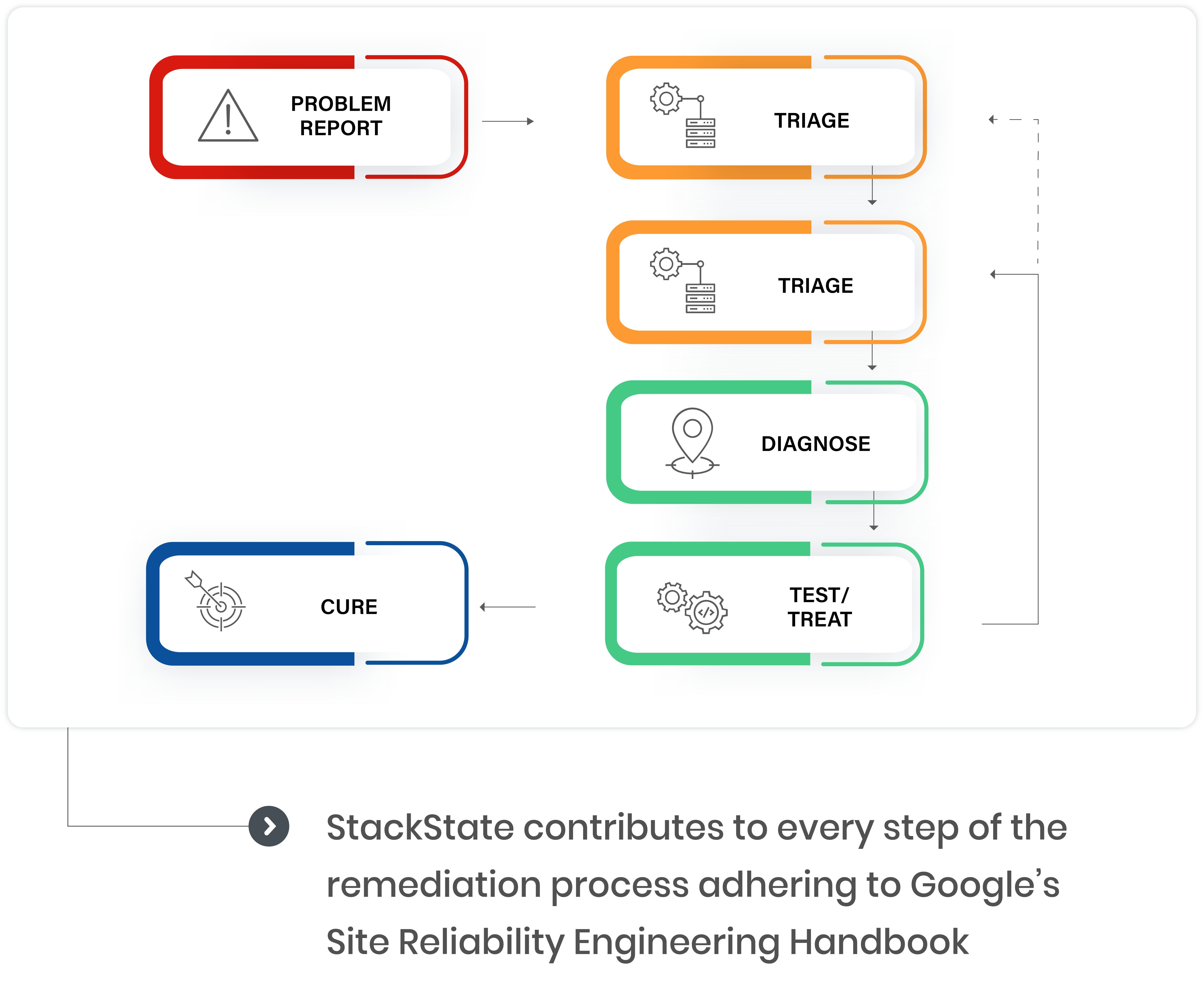
Ready to see it in action?
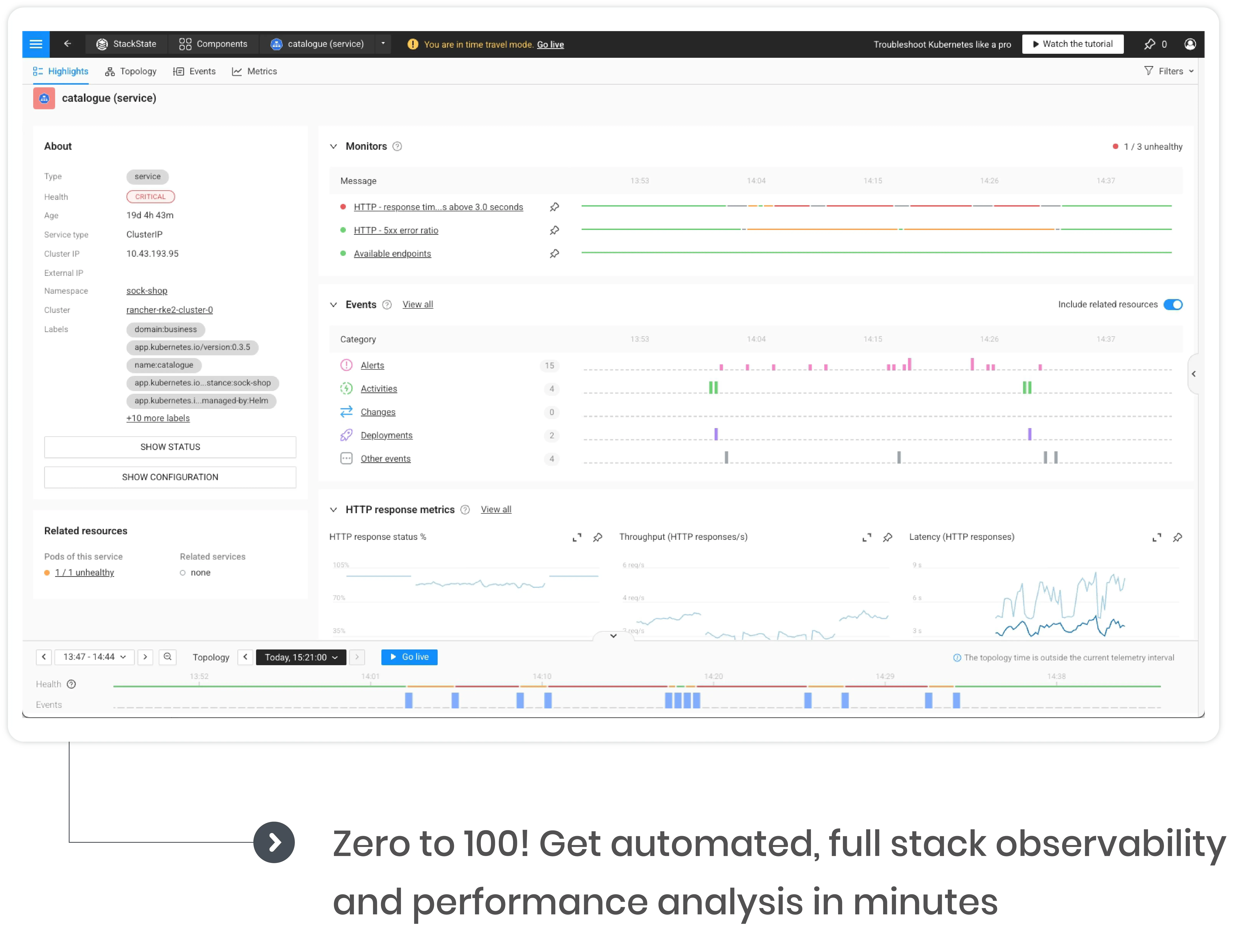
Pinpoint opportunities to take app reliability to the next level
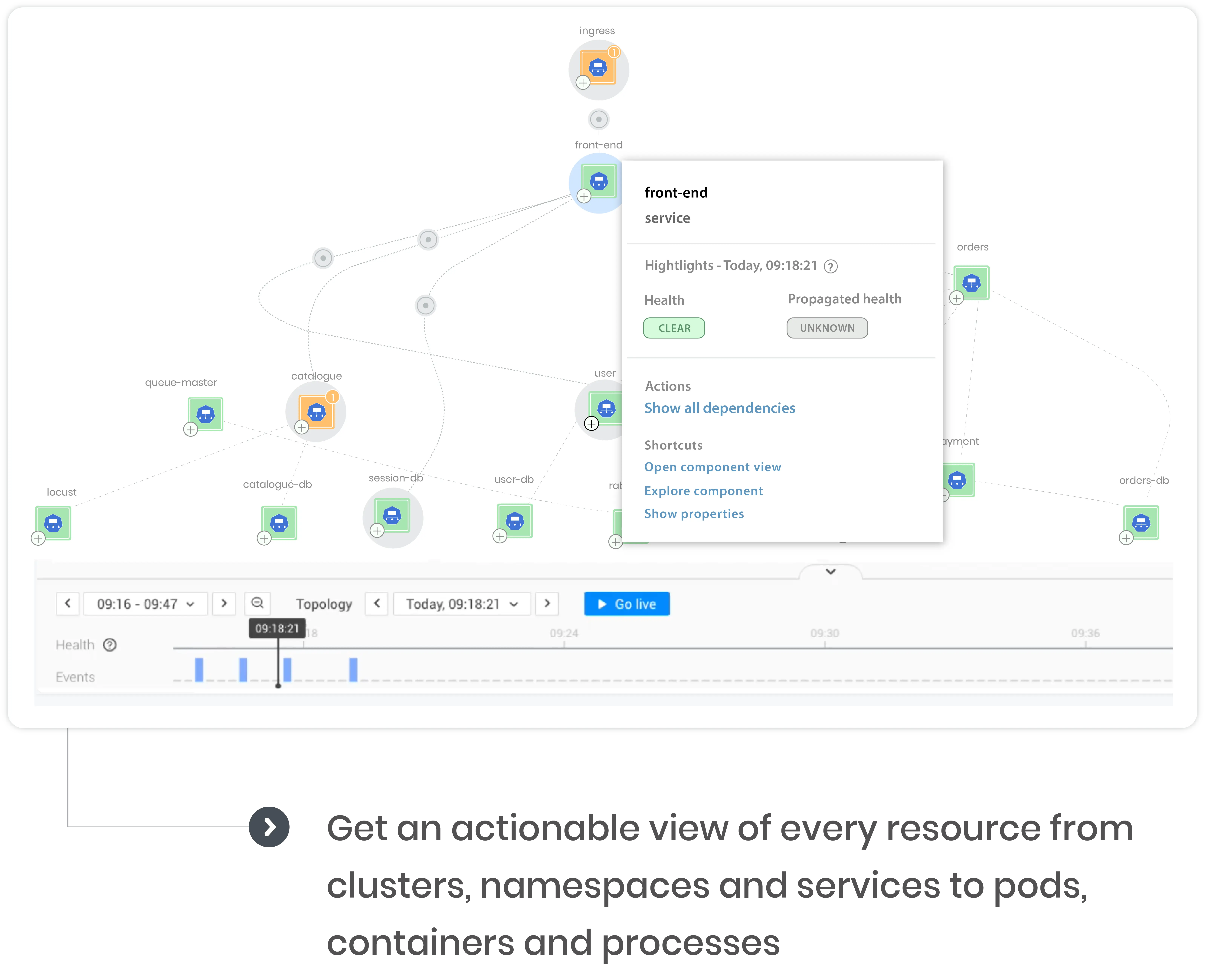
Identify key areas in your Kubernetes environment lacking SLIs
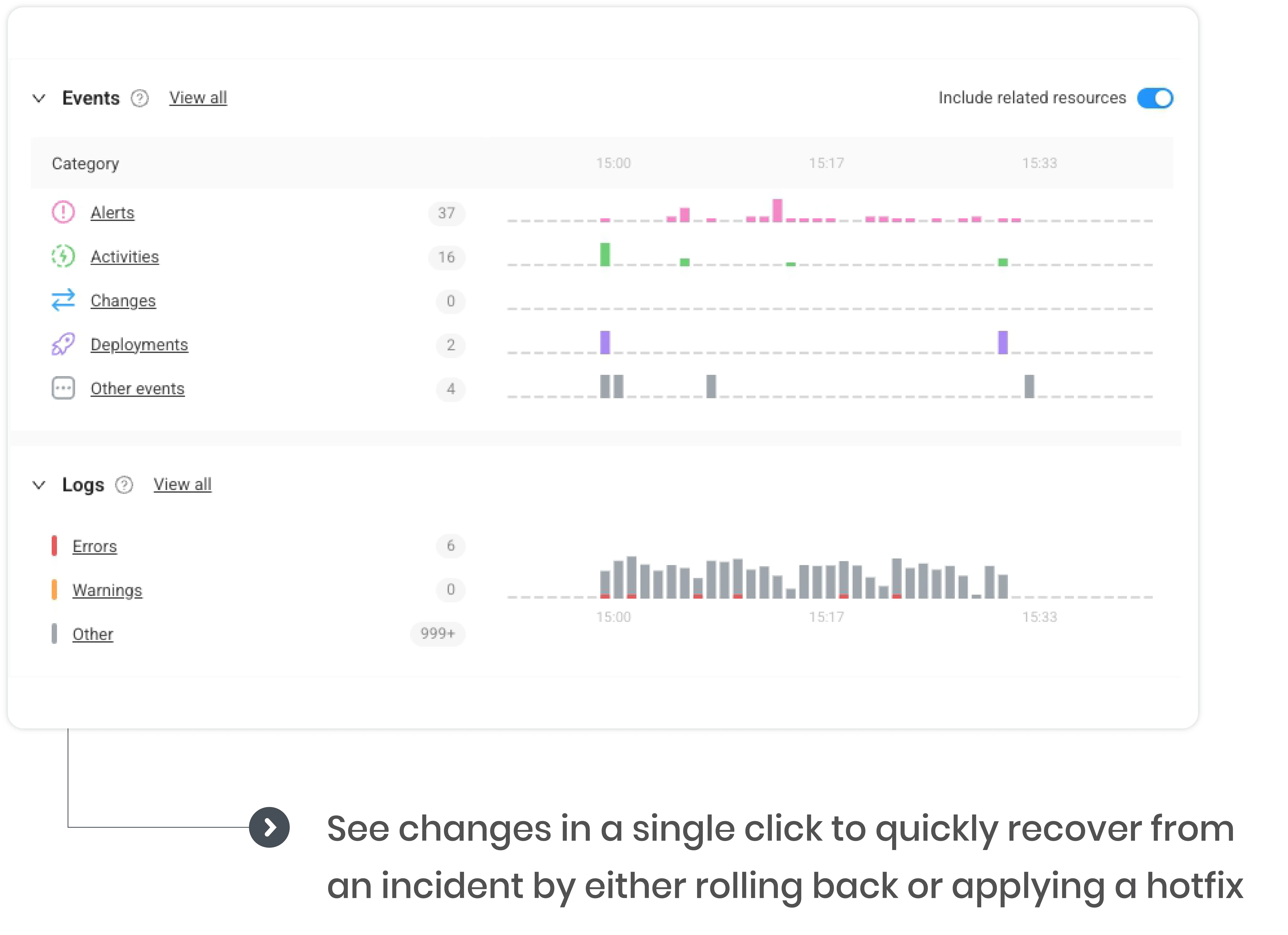
Detect performance degradation and spot weak areas before alerts trigger
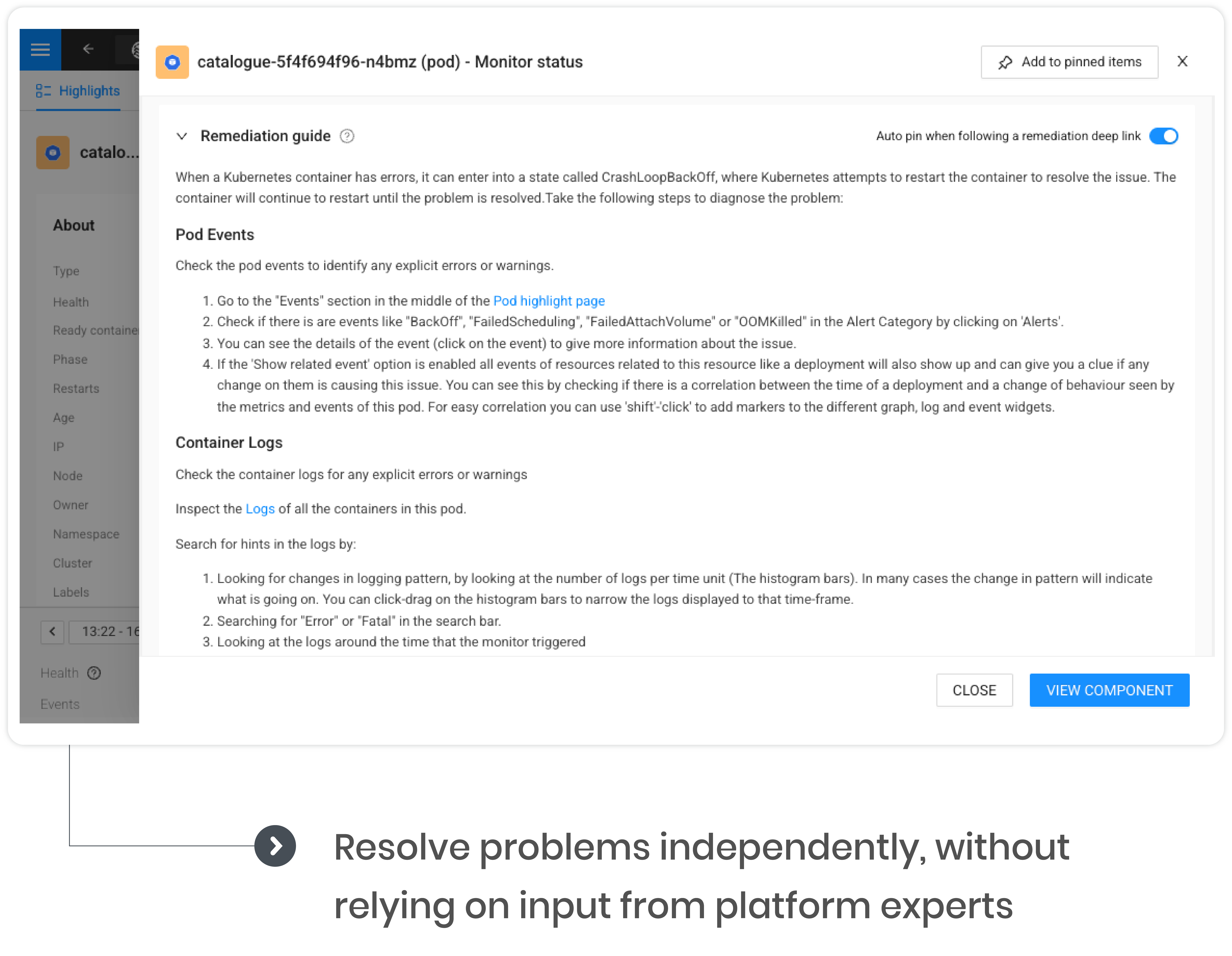
Eliminate context switching and the need for multiple tools
Translate complex issues into dev-related terms, making Kubernetes accessible to all