Hi, I’m Lodewijk Bogaards and I’m the CTO and co-founder of StackState. I’d like to tell you a little bit about the zero downtime enterprise and how we enable you to aim for zero.
The journey to becoming a zero-downtime enterprise starts with being able to quickly identify issues and remediating the root cause before it impacts the business. That’s what companies like Vodafone, KPN, NN Bank, Accenture and dozens more are striving for with StackState.
Three reasons relating root cause to business impact is a huge challenge
Understanding problems from root cause to business impact is a huge challenge for most companies today for several reasons:
1. IT environments are constantly changing
First, dynamic IT environments are constantly changing. Every change introduces risk. When problems occur, it’s difficult – if not impossible – to identify the change that’s causing the problem, ironically because the IT environment looked so different at the moment that the issue started before it actually caused an impact.
2. Information about the IT environment is siloed and incomplete
Second, information about the IT environment, its health and its relationships and dependencies is siloed and incomplete. It is very common for enterprises to have dozens of monitoring solutions – and that’s likely never to change because there is so much activity going on in these environments.
Those siloes can make it very hard to extract actionable information and to coordinate resolution efforts. End-to-end visibility is always lacking. It is very hard for enterprises to separate the noise from the signal.
3. Enterprises are reacting instead of "proacting" to IT problems
And third, because those environments are so dynamic and because there are so many tools and silos, most companies are reactive to problems rather than proactive.
Without a reliable way to pinpoint the root cause, performance degradations and outages cost companies millions each month, consuming time and human resources and negatively impacting reputation and customer satisfaction.
We help enterprises decrease downtime
That’s where StackState comes in. StackState helps enterprises decrease downtime and prevent outages by breaking down the silos between existing monitoring tools and tracking changes in dependencies, relationships and configurations over time. The system relates these changes to incidents, understanding the precise change that is creating the problem. Our clients realize decreases in mean time to repair (MTTR), fewer outages and lower costs associated with incidents.
Lots of monitoring data, still many errors
StackState was born out of a real-life customer problem. A leading bank in Europe was experiencing massive outages in their mobile banking experience and having trouble identifying why, despite the fact that a lot of monitoring data was available.
My StackState co-founder, Mark Bakker, and I were tasked with solving the issue for the bank. And in the meantime, we learned that other companies were experiencing similar issues. It was costing companies time, money and reputation. Solving this problem became StackState’s mission.
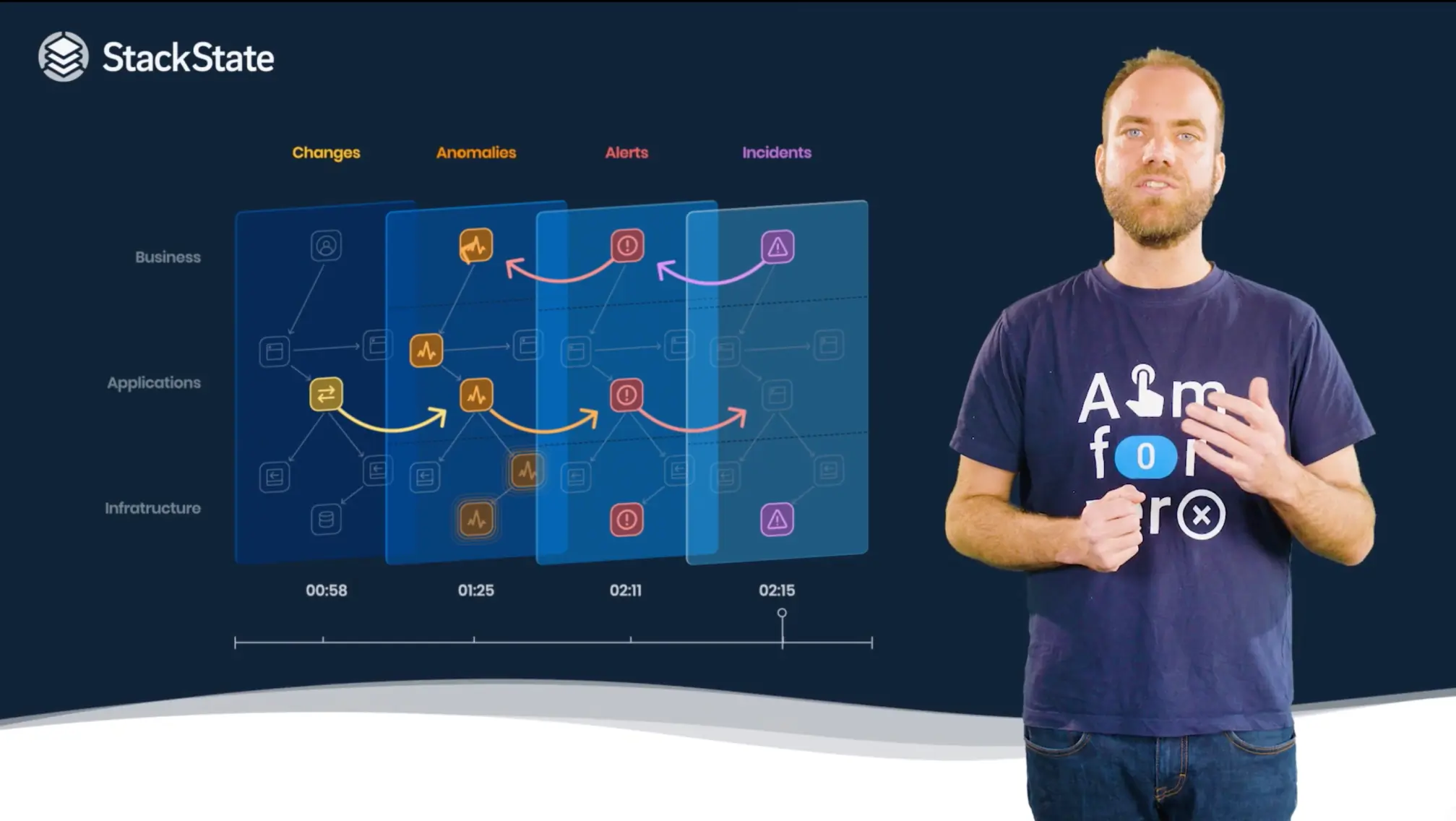
The general path of an IT issue
To become a zero-downtime enterprise, you need to understand the anatomy of an issue. If you look at the post-mortems for problems and incidents, they follow a general path – something changes that causes an anomaly, that triggers an alert, which leads to an incident and triggers an incident management process.
StackState is the only solution that can track the changes at every point in time and link them to the anomalies, that lead to alerts, that result in incidents, helping companies more precisely go from root cause to business impact.
How StackState works
1. Understanding dependencies between IT components
To do that you need to have a few ingredients. First, you need to break down silos of data within your environment.
What we have built is a unique observability solution that integrates with existing tools, like AWS, Azure, Kubernetes, Splunk, Dynatrace and VMware to understand the real-time relationships and dependencies between IT components – from databases and web servers to containers, microservices and applications. We stitch together real-time topological information from multiple sources and track it across time – which solves the dynamic IT problem. We built our own versioned graph database in order to be able to solve that problem. No other vendor offers this.
2. Creating a data model that represents the entire IT environment
Then, we correlate the topological elements with the telemetry that already exists in the environment. We can get to that data without actually needing to copy it to a single place. This creates a seamless data model that represents a customer’s entire IT environment – solving the silo problem. Again, no other vendor offers this.
Underpinning these capabilities is a unique data model that incorporates topology, telemetry and traces from existing tools within the environment and marries it up with our time-based versioned graph database. This is called the 4T Data Model. No other vendor can bring together all of this information, without requiring companies to move their data to our system.
3. Identifying performance anomalies before they become a problem
Finally, we use AI to automatically detect performance anomalies and pinpoint their location in the stack before they have a major impact on business performance – solving the reactive versus proactive problem.
With the 4T® Data Model, StackState is able to track the evolution of a potential problem from root cause to business impact in highly dynamic IT environments, starting with a change, then the resulting anomalies and finally the associated business impact.
Our fundamentally new approach. And vision.
StackState takes a fundamentally different approach than other vendors. And we believe this is the only approach that will work at scale and under all circumstances.
There are still miles to go on the journey to fully realizing the zero downtime enterprise. To this end, StackState continues to add support for modern IT experiences, such as cloud native application environments and, with AIOps, we are maturing our autonomous anomaly detection to further predict and prevent outages before they occur. Finally, we are constantly expanding the monitoring and automation tooling we integrate with.
Follow our journey and learn more by following us on LinkedIn , Twitter , watch our product overview video or book a live demo with one of our consultants.


